

一、提出原因
1、堆叠网络造成的问题
传统的想法是如果我们堆叠很多很多层,或许能让网络变得更好。
然而现实却是:堆叠网络后网络难以收敛,而且梯度爆炸(梯度消失)在一开始就阻碍网络的收敛,让网络难以训练,得到适当的参数。
2、解决深度网络的退化问题
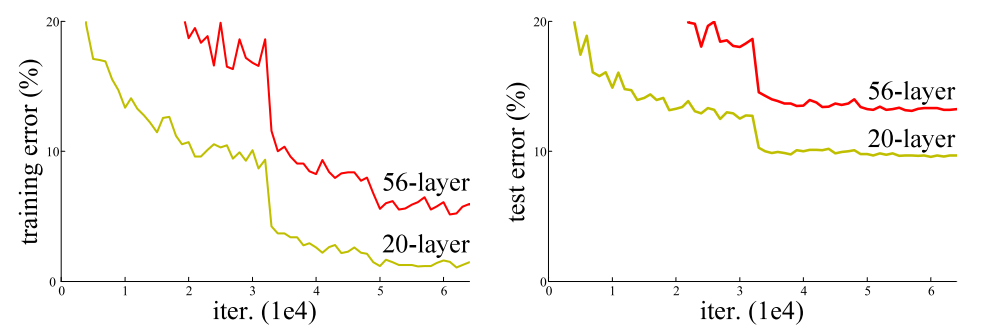
理论上来讲,增加网络的层数,网络可以进行更加复杂的特征提取,可以取得更好的结果。但是实验发现深度网络出现了退化问题,如下图所示(图片来源:Resnet的论文)。网络深度增加时,网络准确度出现饱和,之后甚至还快速下降。而且这种下降不是因为过拟合引起的,而是因为在适当的深度模型上添加更多的层会导致了更高的训练误差,从而使其下降。
二、残差结构
为了解决以上两个问题,残差结构应运而生。
原理图如图所示(图片来源:Resnet的论文):它的结构很像电路中的短路,因此被称为短路连接(shortcut)。
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,下面是这个resnet的网络结构:
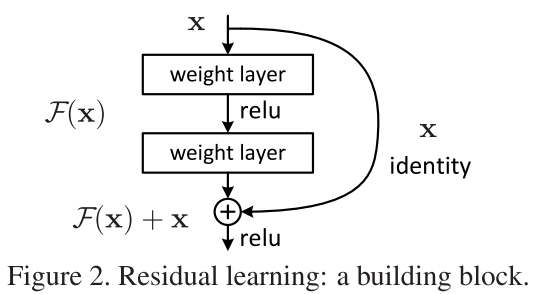
对于这整个堆叠结构,当输入x时:
- 它学习到的特征记为H(x)
- 因此我们希望他学习到的残差为F(x)= H(x)- x;
- 那么我们最初学习到的特征就是H(x)= F(x)+ x。
它对每层的输入做一个reference(X), 学习形成残差函数, 而不是学习一些没有reference(X)的函数。这种残差函数更容易优化,能使网络层数大大加深。在上图的残差块中它有二层,如下表达式,
其中σ代表非线性函数ReLU。
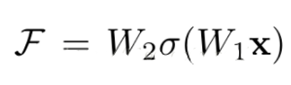
然后通过一个shortcut,和第2个ReLU,获得输出y。
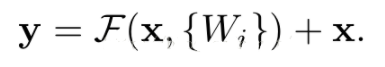
当需要对输入和输出维数进行变化时(如改变通道数目),可以在shortcut时对x做一个线性变换Ws,如下式。
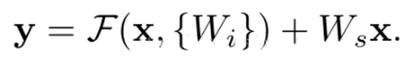
这样做的目的是:让经过堆积结构学到的(F(x))和最原始的x进行联合获取特征。
残差学习相比原始特征直接学习更容易。取一个最极端的结果来看,就是F(x)= 0(堆积结构啥也没学到),这里堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。并且将残差置为零比通过一堆非线性层来拟合恒等映射更容易。
然而实验证明x已经足够了,不需要再搞个维度变换,除非需求是某个特定维度的输出,如是将通道数翻倍,如下图所示:

由上图,我们可以清楚的看到“实线”和“虚线”两种连接方式, 实线的Connection部分 (第一个粉色矩形和第三个粉色矩形) 都是执行3x3x64的卷积,他们的channel个数一致,所以采用计算方式:
Y = F(x) + x,虚线的Connection部分 (第一个绿色矩形和第三个绿色矩形) 分别是3x3x64和3x3x128的卷积操作,他们的channel个数不同(64和128),所以采用计算方式: y=F(x)+Wx 。其中W是卷积操作,用来调整x的channel维度。
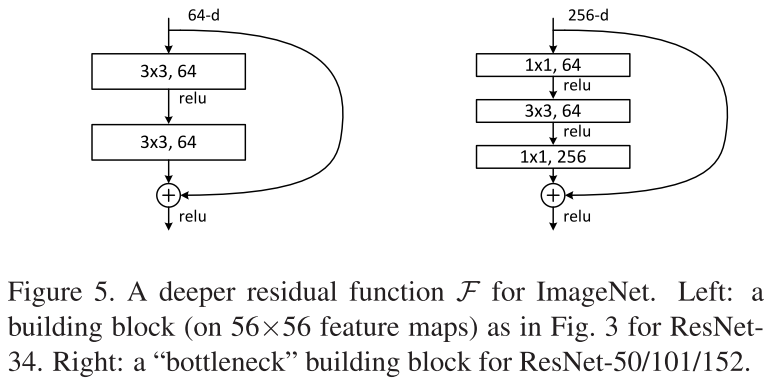
残差块的两种结构
这是文章里面的图,我们可以看到一个“弯弯的弧线“这个就是所谓的”shortcut connection“,也是文中提到identity mapping,这张图也诠释了ResNet的真谛,当然大家可以放心,真正在使用的ResNet模块并不是这么单一,文章中就提出了两种方式:
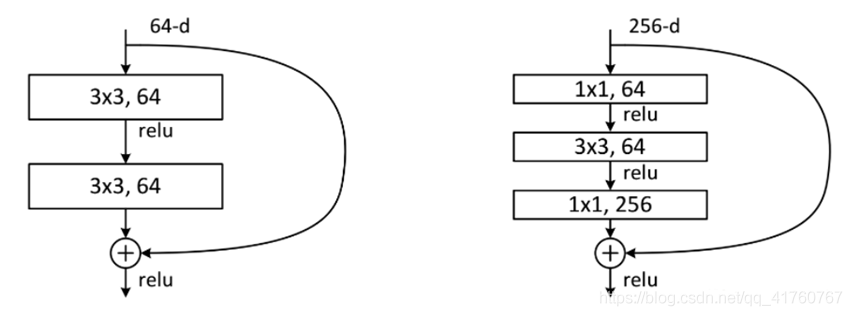
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个“building block” 。其中右图又称为“bottleneck design”,目的就是为了降低参数的数目,实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1,如右图所示。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
三、Resnet网络结构
1.原理分析
ResNet网络是在VGG19网络的基础上进行修改的,并且通过短路机制加入了残差单元。
设计规则:
(1)对于相同的输出特征图尺寸,层具有相同数量的滤波器
(2)当feature map大小降低一半时,feature map的数量增加一倍【过滤器(可以看作是卷积核的集合)的数量增加一倍】,这保持了网络层的复杂度。然后通过步长为2的卷积层直接执行下采样。
网络结构具体如下图所示(左为VGG-19,中为34个参数层的简单网络,右为34个参数层的残差网络):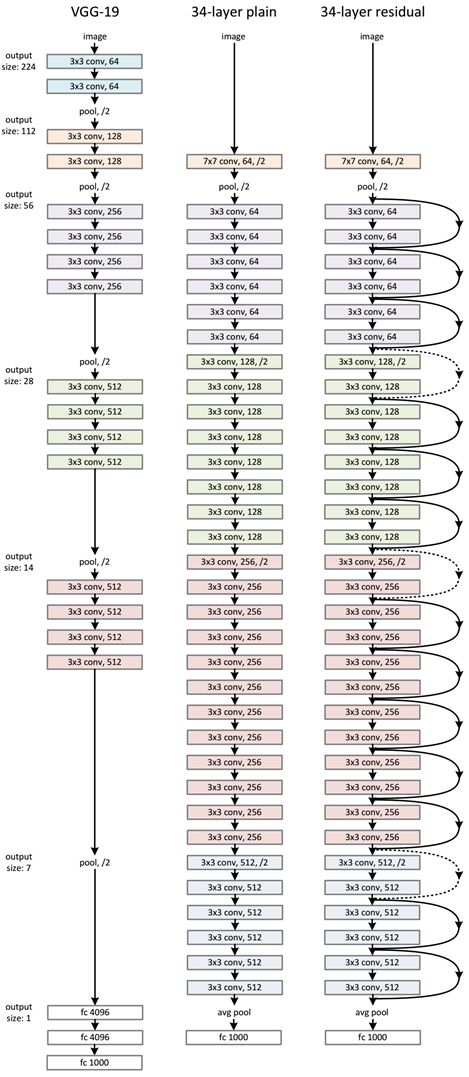
ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中实线表示快捷连接,虚线表示feature map数量发生了改变。
有两种情况需要考虑:
(1)输入和输出具有相同的维度时(对应实线部分):
直接使用恒等快捷连接
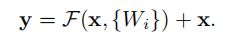
(2)维度增加(当快捷连接跨越两种尺寸的特征图时,它们执行时步长为2):
①快捷连接仍然执行恒等映射,额外填充零输入以增加维度。这样就不会引入额外的参数。
②用下面公式的投影快捷连接用于匹配维度(由1×1卷积完成)
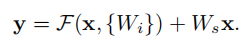
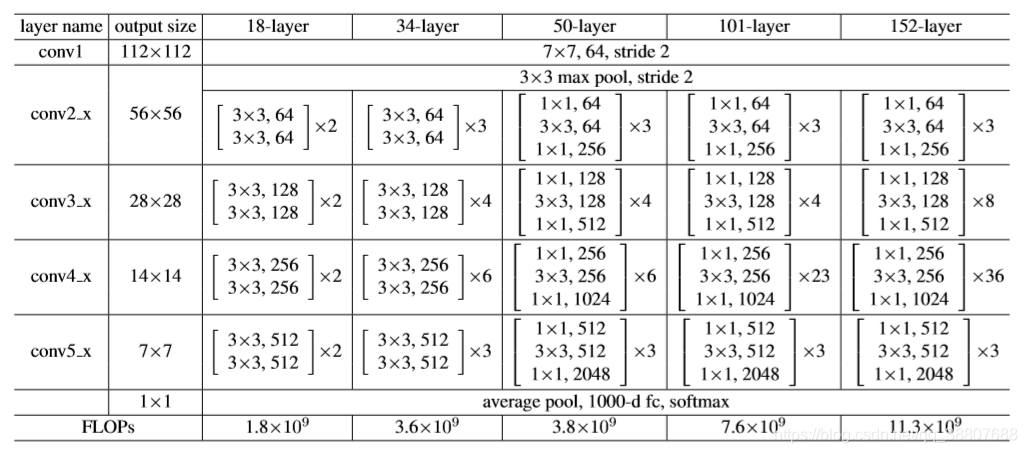
Resnet网络结构的更多细节如下图所示:
2、结构分析
Resnet结构分层为:Layer–Block–Stage–Network
(1)Layer是最小的结构,ResNet-18就代表网络有18层。
(2)Block是由两层或者三层conv层堆叠形成的。一般来说,50层以下用下图左侧的双层block,50层以上用下图右侧的三层block,其中右侧的这个block叫做BottleNeck(瓶颈结构)。
(3)stage 是由数个Block堆叠形成的。如下图黄圈圈(3个Block组成)所示:
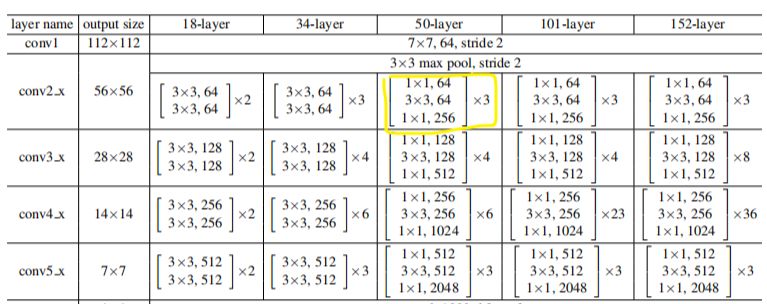
(4)以Resnet-50为例,如上图,该网络是由stage之前的两层(conv7x7, maxpooling)和4个stage(共48层)组成的。
3、代码分析(内含分析和注释)
(1)网络总括
1 | class ResNet(nn.Module): |
(2)内含函数(将多个block拼接成一个stage)
1 | def _make_layer(self, block, planes, blocks, stride = 1): |
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2022/05/07/ResNet/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!