

Sequence to Sequencce
对于自然语言处理中的机器翻译模型中,由于输入输出的序列长度通常不同,所以RNN是不能处理这类问题的,因为对于多少个输入 一定会产生多少个输出 所以LSTM也是一样,所以就需要S to S模型
sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架。一般是通过Encoder-Decoder(编码-解码)框架实现
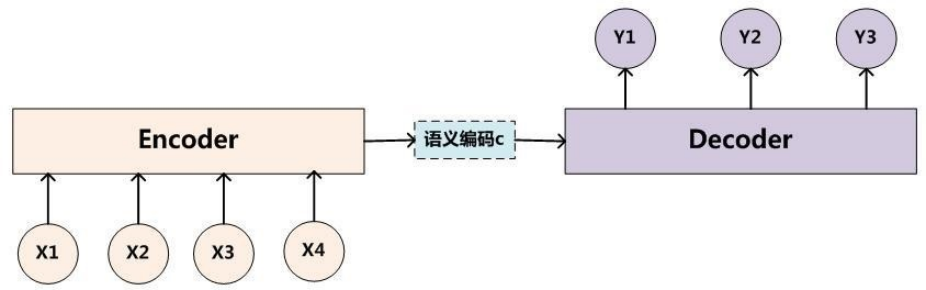
编码过程中 也就是token转化为向量(固定维度的)的过程中会存在信息的丢失。
而且编码过程中的输入序列一般有时序,所以需要在token embedding之后还要加入位置编码
编码结构可以是任意模型 包括RNN LSTM或者transformer中采用的attention
这里三者的优缺点:
- RNN是一个时序模型,也就是下一个时间步的输入需要当前时间步移仓状态的输出以及下一个时间步的token embedding 这样编码之后就可以把最后一个时间步的隐藏状态作为解码器的输入
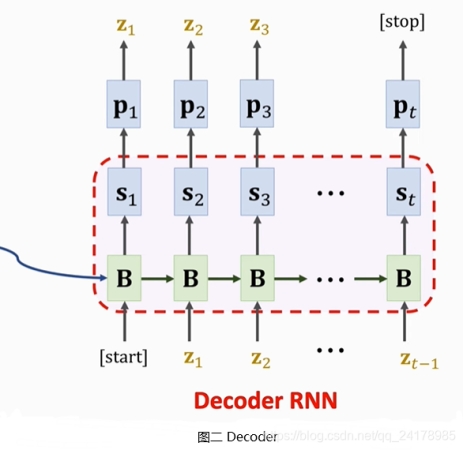
解码器中需要将起始符和编码器的最后一个状态输入RNN,得到初始状态,然后将输入状态通过和权重矩阵计算后过softmax归一化得到所有字符向量的概率,然后基于概率选择z1 token的向量,并作为输入参与下一个字符的预测。但是这样的RNN会存在遗忘的问题,不能处理序列很长的句子token且不能并行,因为上一个时间步的输出作为下一个时间步的输入。
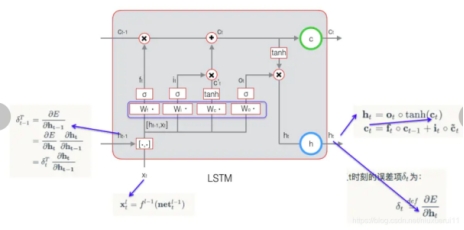
所以可以通过加入门控单元来改良(GRU或者LSTM)LSTM加入了一个cell state来保存长期信息,因为RNN只通过一个隐藏层状态来保存,所以只对短期收益敏感,当序列长度比较长之后会丢失先前的信息。
LSTM设置了三个门控单元,对于遗忘门,将上一个时间步的隐藏单元和当前输入拼接经过一个线性层w1(两个可学习参数,权重和偏置),经过sigmoid将输入转化到0~1的概率,这一步的概率和上一时间步的cell state相乘用于确定上一个时间步的cell state有多少要保存到当前状态。
对于输入门,将上一个时间步的隐藏单元和当前输入拼接经过一个线性层w2(两个可学习参数,权重和偏置),分别过sigmoid 和tanh激活函数,分别得到概率和当前cell state,这里的概率表示避免当前无关紧要(概率小的)的内容进入cell state,就提前给踢掉,最后将遗忘门结果和当前状态cell state相加得到新的cell state。

问题:RNN的梯度消失问题:RNN在处理长序列时,信息需要经过多个时间步才能传递到远处。梯度在反向传播过程中要经历多次乘法操作,若这些乘积项小于1,梯度会指数级地衰减,导致梯度消失。
且如果使用sigmoid激活函数,因为我们的目标就是想让正确的输出概率更大,也就是进入的sigmoid的数就需要很大,那么这个时候的sigmoid的梯度很小,就会导致程序跑不动。当然这也是transformer注意力机制中需要缩放点积(就是需要在计算相似度的时候除以维度大小的原因),因为如果相似度这个数一开始就非常大,然后经过softmax,可能会导致梯度消失,就会导致模型没有提升。
Transformer
优点:
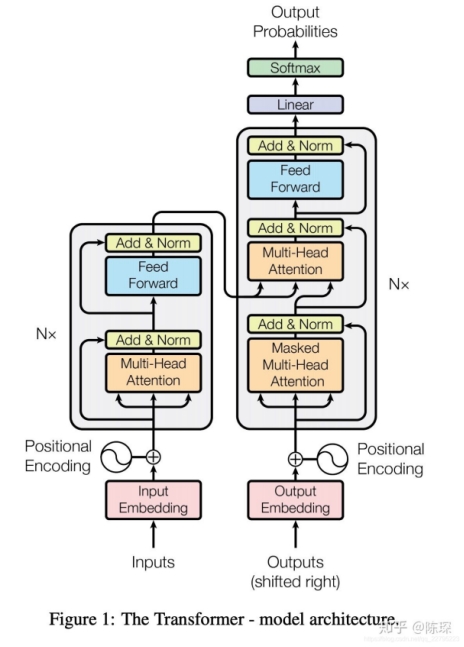
传统的序列处理模型,如RNN和CNN,在处理长序列时,往往会遇到长距离依赖问题。而Transformer模型通过自注意力机制,可以直接关注到序列中的任何位置,有效地处理了长距离依赖问题。此外,Transformer模型的并行性更强,训练效率更高。
位置编码是一种提供序列中单词位置信息的方法。由于Transformer模型没有明确的顺序感知能力,因此需要通过位置编码来提供这种信息。(文章中使用周期函数实现)
Transformer的encoder层
Transformer的Encoder模块主要由两部分组成:自注意力层和前馈神经网络层。自注意力层负责处理输入序列,通过自注意力机制,每个元素可以关注到序列中的任何位置,有效地处理了长距离依赖问题。前馈神经网络层则是一个普通的神经网络,用于进一步处理自注意力层的输出。这两部分都是通过残差连接和层归一化结合起来的,这样可以防止梯度消失,使得模型可以进行深层的训练。
在transformer中计算相似度的时候需要除以向量维度的开方,目的就是如果向量维度比较小的话无所谓,但是当维度比较大的时候(维度小可能无法表示充分的语义,就像前面说的会导致语义信息的丢失),在进行注意力机制相似度计算的时候,不同向量之间的差距也会变大,这样算出来的值就会向两端靠拢,防止相似度的值过大,导致softmax的结果趋于1,导致梯度很小,这样可以将结果控制在一个合适的范围内,可以防止梯度消失,也就叫做缩放注意力机制。
在解码部分的mask多头注意力机制
其中的mask不是在一开始就操作的,而是让模型看到所有的token embedding,并在计算自注意力机制的时候,对于每一个token词的向量作为query(n个querydim向量维度,这里的n就是一个序列的token的个数),是要和所有token作为key(n个key(由于是自注意力所以二者维度一样)dim维度)来进行点积的,算完之后是n*n的一个矩阵,表示n个query(token)和n个key之间的点积,但是这时候还没经过softmax所以还没有生成权重,由于这个矩阵是按照时间排列的(第n行表示最后一个token和n个key的点积),所以只需要将上三角的值全部换成一个很负很小的数,这样在计算权重的时候就会变成0。这就是mask做的事情。
Transformer中的残差结构(具体思想看下面resnet):
网络越深表达能力越强,性能越好。不过,好是好了,随着网络深度的增加,带来了许多问题,梯度消散,梯度爆炸;更好的优化方法,更好的初始化策略,BN层,Relu等各种激活函数,都被用过了,但是仍然不够,改善问题的能力有限,直到残差连接被广泛使用。
通过将原始输入加入下一层中,可以减少信息的丢失,并防止梯度消失的问题,因为每一次计算梯度的时候,都包含一个加项,这样可以防止随着层数的增加,当计算到输入层附近的时候,梯度消失的情况,导致模型学习效果以及loss变差(最关键原因)
在测试时,需要关闭Dropout,即将Dropout的比率设置为0,以确保模型的输出是确定的。
Transformer中全连接层的作用
如果没有全连接层,他们模型只会有self-attention层出来的一些线性组合,表达能力有限,而全连接层可以自己学习复杂的特征表达,通过维度变换(将512维度的向量变到1024)让全连接层学习更加复杂的表达,并且激活函数能提供非线性(目的是增强模型的适应性和表达能力)。
Embedding:
对于模型的输入部分我们通过wordpiece进行分词,也就是得到最后句子序列的token之后,如果使用one hot编码得到的向量是一个高维稀疏向量,不能表达特征,所以采用embedding将高维信息映射到低维向量中称为embedding,embedding其实就是一个向量组,然后我们通过lookup table在里面提取需要实体的向量。
Embedding有两种,一种是不参与训练的,也就是比如使用meaformer预训练好的embedding进入我们的NAS模块训练;另一种是将embedding设置为trainable的,比如transE,对随机初始化的embedding进行训练,让相似的实体更靠近,内积值更大,不相似的实体更远,趋近于正交。
Bert中的mask和transformer的区别:
BERT的mask操作是在输入层进行的,即在输入序列中随机选择一些位置进行mask,然后让模型预测这些被mask的位置的原始值。这种方法的优点是可以让模型在训练时就考虑到序列中的所有位置,从而更好地学习到上下文信息。而在attention处进行mask的方法虽然也可以实现类似的效果,但是它需要在每个位置都进行mask操作,这会增加模型的计算复杂度。因此,BERT选择在输入层进行mask操作,以达到更好的效果和更高的计算效率。
Resnet
Resnet的基本假设 就是模型的层数变多之后,模型会变得复杂,测试loss和精度都会变差,但这不是属于过拟合,而是因为训练的loss和精度也变差了,所以不是过拟合
Resnet提出的就是随着网络层次的增加,不应当网络性能会变差
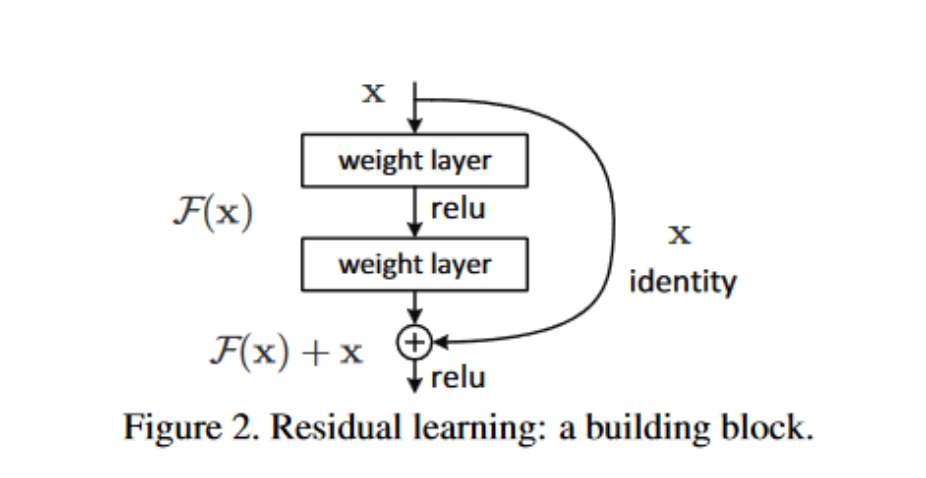
本质上相当于当我们的神经网络特别深的话,就可以设计成一个残差块,图中就是两个layer层中间通过一个激活函数,这样一个结构作为残差块,这个结构的意义就是,就算Fx这个残差块没有起作用,没有学到一点东西,也没关系,我们可以用之前的模型作为输入进入下一个模块,这使得模型可以通过学习残差函数(Fx)来提高性能,而不是直接对原始未参考输入的函数,这样的话,我们学习的模型一定会比不包含这个残差块以及后续函数的模型要更好,而且不会因为模型深度的增加而导致模型变差
如果说残差块中的卷积神经网络会导致模型的输入通道改变,我们需要对原始输入x进行1*1卷积核以及不同stride步长的卷积和padding,从而改变原有输入的通道数,这样就可以在+部分进行相加了。
BERT
Bert有两个步骤:预训练和微调
Bert中transfomer的可学习参数数量
对于embedding部分,都是可以trainable的,所以看一共有多少个词(token=30k),每一个token的emebding的维度是H(512),然后对于自注意力机制,query、key和value都是同一个token embedding序列(假如又n个embedding,那就是nH),然后需要对这三个矩阵进行投影,因为是多头注意力机制,需要将这三个矩阵投影到不同的空间,这里假设头数是A,那么每一个投影矩阵的大小就是H(H/A),将这些不同头(空间)投影矩阵拼在一起就是HH的矩阵,而且query key value都有这样几个投影矩阵,最后呢需要将不同空间中的计算得到的加权value和(就是对应不同投影空间的相似度乘上对应value)(这时的value是n(H/A)大小的)进行拼接,组合成(nH)的,在经过一个HH的投影矩阵 给投影回到初始空间,这就是多头注意力机制的过程,最后得到的注意力机制学习到的不同特征的(类似于卷积神经网络的通道数)的信息。
最后再经过一个前馈神经网络,两个隐藏层,分别是将输入特征投影到更大空间的一个投影矩阵(H4H)大小,然后在经过一个(4HH)大小的一个隐藏层,在投影回去,增强模型的表达能力并消解注意力机制中的线性,增强模型非线性。
由于transformer的编码层有L层,所以总的模型参数数量就是embedding的数量30kH + L(8H^2 (前馈神经网络)+3H2(三个投影矩阵的拼接)+H2(最后投影回原始空间的矩阵)
Transformer和Bert的不同:
Bert只有编码器,而transformer还有解码器,transforner的输入是一个句子对,因为一开始的transformer是作机器翻译的,所以分别是翻译前后的句子,而bert只有编码器,但是他的输入可以是一个序列,其中可以包含一个句子,也可以是两个句子,也可以是一个单纯的单词排列的序列。
所以bert学习了一个embedding,分别由token embedding、position embedding位置编码以及句子编码,也就是如果有两个句子的话,需要区分他们是第几个句子,并且如果有两个句子,还要包括CLK起始embedding和SEP区分embedding这两个特殊的embedding
Bert的应用
因为bert没解码层,所以没办法作机器翻译这个任务了,但是由于bert的输出就是为了学习每一个token的表示embedding,所以如果我们想要做的是多酚类任务的话,就可以输入句子以及CLS这个token,最后学习这样一个CLKembedding,最后将这个嵌入经过一个全连接层,再提取每一个类别的可能性,然后经过一个softmax得到每一个类别的概率。
GPT
1 NLP的下游子任务有很多且差别很大,没有办法训练一种表示可以运用在所有的子任务上面(没有免费的午餐)
2 提出了一个半监督的方法,在没有标号的文本上面训练出一个比较大的语言模型,并在子任务上微调
3 半监督学习:可以在没有标号的数据中进行训练,然后在有监督的数据上进行微调这是一种方法,也可以叫做自监督模型
4 Transformer在迁移学习当中相比于RNN来说学习到的feature更加的好,可能是因为transformer可以看到更多的信息,更好的提取句子和段落层面的整体信息。
5 模型架构
5.1. 无监督训练 (自监督模型)
这是一个标准的语言模型,所以在预测的时候是不能像编码器那样在自注意力机制时query和key点积的时候看到所有的词,所以需要使用解码器在softmax之前使用mask给掩盖掉。
如果要预测第u个词的话,就需要把序列中u前面的词都拿出来,做一个词嵌入的投影,也就是embedding,再加上一个位置编码的embedding,然后进入transformer的解码层,由于transformer的结构是不会改变输入输出的维度和结构的,所以可以重复L层,从而提取更多的信息。
最后得到是一个序列(token有n个)经过mask的n层自注意力机制加权和的向量,也就是ndim的维度,然后经过一个dim单词表总数(比如上面写的token字典总数是30k)的一个全连接层,在经过一个softmax就得到了给定当前n个token的序列的下一个词是什么所有概率。这就是解码器的原理。
这就是和bert不同的地方,bert是进行完形填空,也就是挖掉序列中的某几个词,然后通过transfomer编码器和解码器一样得到这个序列的一个向量,然后应该是将需要预测的一些词的向量拼接,投影到整个词表中softmax得到所有的词的概率。

对于bert当中,对于掩码模块就是将最后的掩码embedding(ndim,n表示有多少个token的嵌入被替换城mask了,dim表示向量的维度)拿出来并经过一个全连接层(dimL,L表示词典里面一共有多少个token)投影到词表的空间,然后得到这些掩码和词表中token的相似度,通过softmax得到,然后取出来之后和正确的进行交叉熵计算loss。
5.2. 微调
微调的任务就是给定一个句子的序列,然后将这个句子序列放到解码器中,找到最后一层transformer块的输出的最后一个词的embedding,然后将其投影到序列标号(任务是给定序列预测这个句子的标号,投影矩阵的大小就是embedding’s dim * 序列总数)当中,softmax得到这个句子到底是哪一个标号的概率。
当然在微调的时候也可以加入训练时候的损失函数,也就是给定前面一个词预测下一个词的概率,这个也是一个自回归的过程
auto-regressive自回归,过去的输出作为当前时刻的输入,就是解码器的输出可以作为下一次输出的输入。
微调的任务 包括:分类(和蕴含一样,就把一个句子放到解码器中,通过线性层投影到类别空间 也就是dim类别数目的这样一个投影矩阵),蕴含(两个序列拼接起来,用一个分隔符分开,然后将这整个的序列放到transformer中,经过llinear投影到2值空间,判断是否蕴含),相似(由于a和b相似和b和a相似是一个意思,但是语言模型句子是有先后关系型的,所以就分别经过解码器得到两个结果拼接经过linear投影到二值空间)多选题(分别将题目和四个答案进行拼接进入GPT,得到每一个答案最后一层的最后一个token的词向量投影到一个二值空间,然后对这三个数进行softmax得到这三个答案的概率)
GPT2
针对GPT1的问题做出了回答,就是对于每一种下游任务,还是要花费成本去训练微调(因为训练是无监督训练,但是微调是需要有标号的数据来调整的)来适应不同的下游任务,GPT2提出了zero-shot。
- Zero-shot
不需要有标注的信息来微调,只需要训练一个预训练模型,可以直接适应一个下游任务。
- One-shot
就是给一个示例,然后求解一个新的类似的任务
- Few-shot
就是还需要一些样本来对模型继续更新
- 一直说的这个SGD指的就是梯度下降法
GPT3
针对GPT2的问题做出了回答,虽然GPT2提出不需要任务微调就可以直接应用在下游任务当中,但是效果不佳,所以gpt3改成了few shot同样需要很少的一点样本,但是在微调的时候不需要算梯度,因为参数太多了,很难承担计算梯度反向更新的成本。所以模型提出了两个名词
- Meta-learning
- In-context learning
分别给出了不同数目的示例来进行预测。我们需要注意的是,这一步骤是没有任何学习的,并没有梯度回传,你可以把它理解成为一个非常详细的prompt,让模型学习到内在的逻辑,进而进行预测。
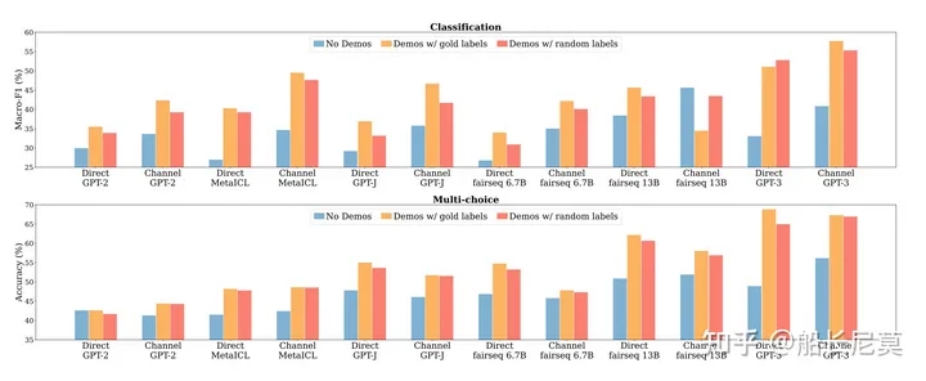
其中蓝色列是无标签,正确标签是橘红色,随机标签是红色。其中红色的部分比橘红色的,没有低多少,也就意味着即使label是随机打乱的,对于结果的影响也很小
论文中的解释是:模型能够恢复任务的预期输入-标签对应关系;然而,这并不是直接从演示中的配对中获得的。因为这部分ICL并不是有梯度更新的,所以让模型理解一个标签的含义不太切合实际,但是呢,这点确可以让模型知道,标签的大概范围,例如有多少种之类的。
2.1. ICL有效的原因
*训练数据分布:*模型在大量的语料预训练过程中,学习到大量的 “concept”。“concept” 可以看作是一个潜在的变量,变量包含多种多样文本级别的数据。“concept”结合非常多的潜在变量指定了一个文本语义的方方面面。
*学习机制:*有学者猜测 LM 可能自己就具备学习的能力,在做 ICL 的时候学到了这些知识,或者隐式直接精调了自己。
*Transformer模块:*有学者发现 Transformer 里的某些注意力头会通过拷贝固定的模式来预测下一个token
*InstructGPT*
引入强化学习RLHF模型
在GPT3后面模型的提示和问题的输入就是prompt
SFT(ScalableFine-Tuning)是一种用于自然语言处理的技术,它通过对预训练的语言模型进行有监督微调,使其适应特定任务。
GPT-1是在每个NLU(NLU是所有支持机器理解文本内容的方法模型或任务的总称)任务上训练一个模型,而InstructGPT是训练一个通用的多任务模型出来。另一方面,GPT-1只是做了Supervised Learning,InstructGPT则是用Prompts+Response Demonstrations自由文本作为训练数据,走了一条Supervised Learning和Reinforcement Learning流水线。
KG inhanceed LLM
- KG增强的LLM
LLMs常因其幻觉问题而饱受诟病,且缺乏可解释性。为了解决这些问题,研究人员提出使用知识图谱( Knowledge Graph,KG )来增强LLMs。知识图谱以结构化的方式存储了大量的知识,可以用来增强LLMs的知识。
可以在预训练阶段将KGs融入到LLMs中,或者在推理阶段将KGs纳入LLMs。
KG增强的LLMs。集成KGs可以增强LLMs在各种下游任务中的性能和可解释性。我们将KG增强LLMs的研究分为3组:
其目的是在预训练阶段为LLMs注入知识。然后,我们引入了KG增强的LLM推理,使得LLM能够在生成句子的同时考虑最新的知识。最后,我们引入KG增强的LLM可解释性,旨在利用KG提高LLM的可解释性。
现有的KGs方法在处理不完整KGs [ 25 ]和处理文本语料构建KGs [ 96 ]方面存在不足。随着LLMs的可推广性,许多研究人员正试图利用LLMs的力量来解决KG相关的任务。将LLMs作为文本编码器应用于KG相关任务的最直接的方法。研究者利用LLMs对知识图谱中的文本语料进行处理,然后利用文本的表示来丰富知识图谱表示[ 97 ]。一些研究还使用LLMs对原始语料进行处理,提取关系和实体用于KG构建
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/11/06/各类模型总结/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!