

为什么Diffusion Models钟爱U-net结构
最近在看很多关于Diffusion Model的工作,几乎所有的工作都选用了U-net,U-net这其中的作用是在反向过程中预测噪声$$。
可是为什么一定要用U-net呢?
为什么几乎所有的工作都是在U-net的基础上呢?(部分3D generation选用MLP)
我们依次来进行探究。
灵感从GANs中来
首次在深层次生成模型中使用U-net结构的是2017年发表的论文《Image-to-Image Translation with Conditional Adversarial Networks》,也就是大名鼎鼎的Pix2Pix GAN。
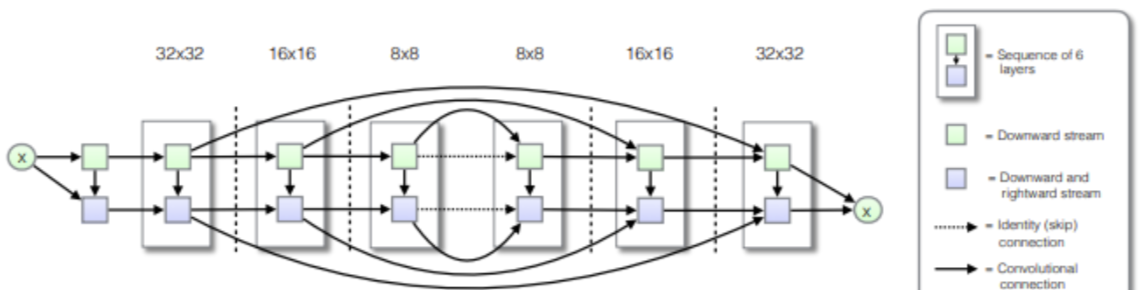
在U-net网络中,输入通过一系列层,逐步下采样,直到bottleneck层,在这一点上,过程是反向的。这样的网络要求所有的信息流都要经过所有的层,包括bottleneck。对于许多图像翻译问题,在输入和输出之间有大量的低级信息共享,因此希望将这些信息直接通过网络传递。
为了能让这些信息顺利传递,在用于医疗分割的《U-net:Convolutional networks for biomedical image segmentation》基础上,加入了jumper layer,在第i层和第n层之间添加jumper layer,其中n为总层数。每个jumper layer将第i层的所有信道与第n-i层的信道连接起来。
为了说明U-net的有效性,作者做了消融实验,将jumper layer切断,变成了一个简单的encoder-decoder的结构,生成的效果对比如下图:

DDPM诞生之初与Unet的不解之缘
《Denoising Diffusion Probabilistic Models》是第一篇提出DDPM的文章,在文章中,使用了PixelCNN++,这是一个基于wide resnet的U-net结构。
虽然DDPM需要生成器预测噪声的分布,但是此处噪声可以看成数据分布的增广,我们需要一个具有强大能力的生成网络,因此选择了PixelCNN++网络。
Positional Embedding 融入共享参数信息
原有的U-net结构不能完全满足扩散模型的需求,我们需要做一些改进,其中融入共享参数信息是首先要解决的问题。
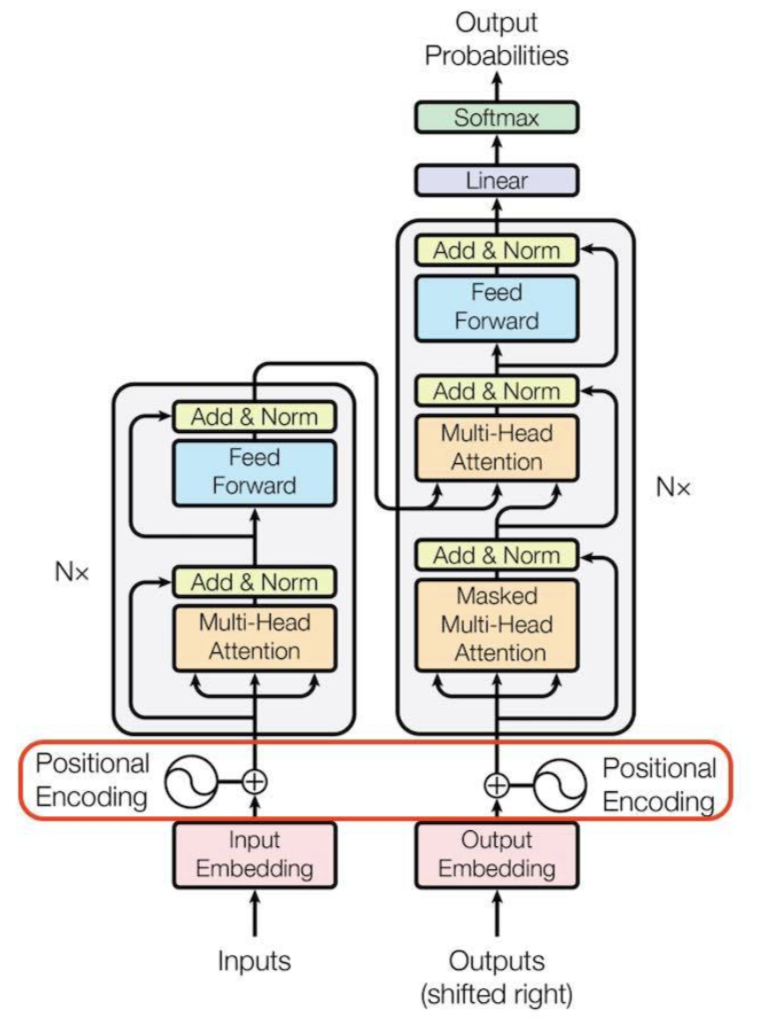
Positional Embedding 是 transformer中一个重要的组成部分,因为在transformer中不包含RNN和CNN,为了让模型利用序列的顺序,必须注入一些关于序列中记号的相对或绝对位置的信息。
为此添加位置编码在编码器和解码器堆栈的底部。位置编码与具有Embedding vector具有相同的维数模型,因此可以将两者相加。位置编码可以是可学习的,也可以是固定的。原始的transformer中将奇数和偶数位置分开,计算公式如下: \[ PE\left( pos,2i \right) =\sin \left( pos/10000^{2i}/d_{mode} \right) \] \[ PE\left( pos,2i+1 \right) =\cos \left( pos/10000^{2i}/d_{mode} \right) \]
但是在diffusion model当中做了一些简化:
1 | self.positional_embedding = nn.Parameter(th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5) |
U-net基础上引入self-attention机制
transformer火了之后,attention机制也随之非常流行,U-net结合attention并不是DDPM首次提出,DDPM在U-net基础上引入了self-attention机制,在特征图分辨率上使用自注意力机制。自注意力机制是一种将单个序列的不同位置联系起来以计算序列的表示形式的注意机制。自我注意在阅读理解、抽象摘要、文本蕴含和学习任务独立的句子表征等任务重都得到了成功的应用。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
原先的transformer在encoder和decoder中使用自注意力机制,也就是上面图中的multi-head attention。计算公式如下: \[ Attention\left( Q,K,V \right) =soft\max \left( \frac{QK^T}{\sqrt{d_k}} \right) V \] 每个attention模块都在每一层的卷积块中间添加,具体的DDPM的attention机制代码如下:
1 | class AttentionBlock(nn.Module): |
总结
- U-net的生成能力在GANs中早已被证明是强大有效的
- 在之前U-net结构的基础上,加入了attention和PE,形成了DDPM特有的U-net结构
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/11/13/为什么Diffusion-Models钟爱U-net结构/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!