

前言:CVPR 2022中的一项新工作latent diffusion models引起了广泛关注,提出了两段式diffusion models能有效节省计算资源,latent attention技术为通用image-to-image任务打下基础,让人耳目一新,具有极强的借鉴意义和启发性,值得深度阅读。
目前Diffusion Models存在的问题:高昂的计算代价
通过将图像形成过程分解为去噪自编码器的顺序应用,扩散模型在图像数据等方面取得了最先进的合成结果。此外,它们的表述允许一个指导机制来控制图像生成过程,而无需重新训练。然而由于这些模型通常直接在像素空间中操作,功能强大的diffusion models的优化通常会消耗数百个GPU天,并且由于顺序评估,推理成本很高。为了使diffusion models在有限的计算资源上进行训练,同时保持其质量和灵活性,将它们应用于强大的预训练自编码器的潜空间中。与之前的工作相比,在这种表示上训练扩散模型首次允许在降低复杂性和保留细节之间达到一个近乎最佳的点,大大提高了视觉保真度。
通过在模型架构中引入交叉注意力层,将扩散模型变成了强大而灵活的生成器,用于一般的条件输入,如文本或边界框,并可以以卷积的方式进行高分辨率合成。潜扩散模型(LDMs)在图像修复和类条件图像合成方面取得了新的最先进的分数,并在各种任务上具有高度竞争力的性能,包括文本到图像合成、无条件图像生成和超分辨率,同时与基于像素的DMs相比,显著降低了计算需求。
总结:作者还扯了一下环保的问题,前人的工作不环保,我的工作也不环保,但是我的工作能复用,所以我的工作环保,就是这么牵强,但是谁让人家效果好呢~
主要贡献
- Difusion model是一种likelihood-based的模型,相比GAN可以取得更好的生成效果。然而该模型是一种自回归模型,需要反复迭代计算,因而训练和推理都十分昂贵。本文提出一种diffusion的过程改为在latent space上做的方法,从而大大减少计算复杂度,同时也能达到十分不错的生成效果。 ( "democratizing" research on DMs) ,unconditional image synthesis, inpainting.super-resolution都能表现不错~
- 相比于其它进行压缩的方法,本文的方法可以生成更细致的图像,并且在高分辨率(风景图之类最高达1024*1024都无压力) 的生成也表现得很好。
- 提出了cross-attention的方法来实现多模态训练,使得class-condition,text-to-image,layout-to- image也可以实现。
方法详解
两阶段训练:
- 第一阶段:训练一个auto-encoder,它提供一个低维的表示空间,其实就和数据空间等效。这样有一个好处:只需要训练auto-encoder一次,这个encoder就可以用于其他的DM训练。
- 第二阶段:训练DM
对于T2I的任务,专门设计了一种架构,将transformer连接到DM的U-Net Backbone,并且使用了一种基于令牌的调节机制。
auto-encoder降低计算复杂度
为了降低训练扩散模型对高分辨率图像合成的计算需求,尽管扩散模型允许通过对相应的损失项欠采样来忽略感知上不相关的细节,但它们仍然需要在像素空间进行昂贵的函数评估,这导致了巨大的计算时间和能量资源需求。
文章引入压缩与生成学习阶段的显式分离来规避这一缺点。为了实现这一目标,本文利用一个自编码模型,该模型学习一个在感知上等同于图像空间的空间,但提供了显著降低的计算复杂度
如下图所示:
- 横轴是隐变量每个维度压缩的bit率
- 纵坐标是模型的损失
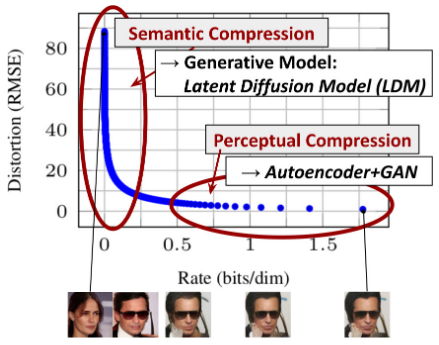
模型在学习的过程中,随着压缩率变大,刚开始模型的损失下降很快,后面下降很慢,但仍然在优化。模型首先学习到的是semantic部分的压缩/转换 (大框架),这一阶段是人物semantic部分转变,然后学习到的是细节部分的压缩/转换,这是perceptual细节处的转变。
auto-encoder的方法有几个优点:
- 通过离开高维图像空间,获得计算效率高得多的difusion models,因为采样是在低维空间上进行 的。
- 利用了从其UNet架构继承而来的diffusion models的归纳偏差,这使它们对具有空间结构的数据特别有效,从而减轻了对之前方法所要求的激进的、降低质量的压缩水平的需求。
- 得到了通用的压缩模型,其潜空间可用于训练多个生成模型,也可用于其他下游应用,如单图像片 段引导的合成。
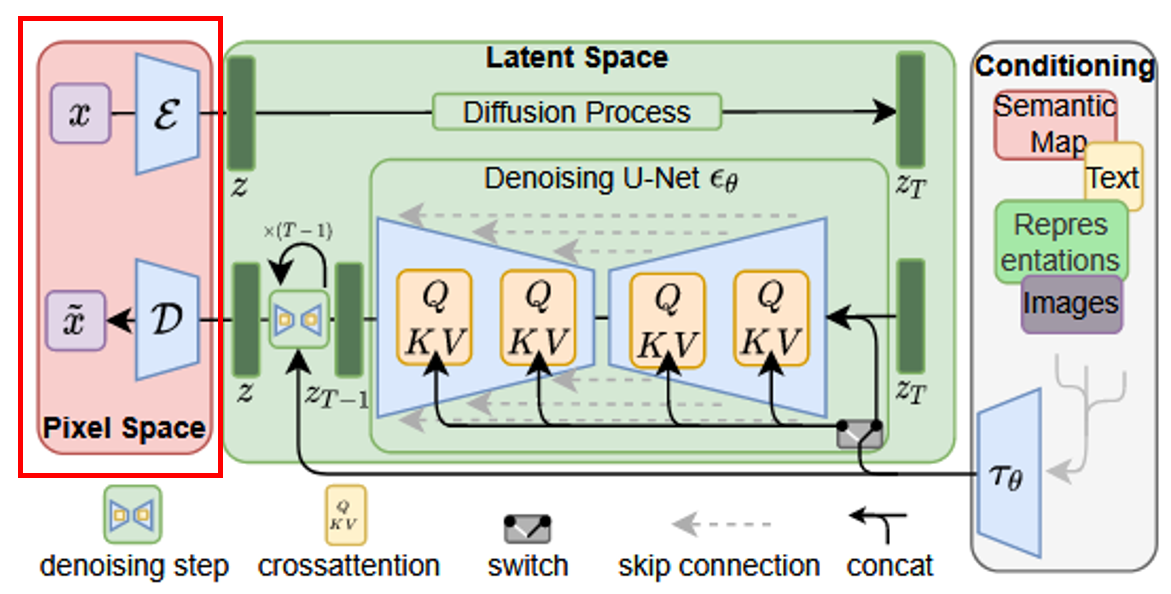
下面红框中的部分就是auto-encoder:
很牛波一的Attention
下图红框中的部分是作者对attention的改进:
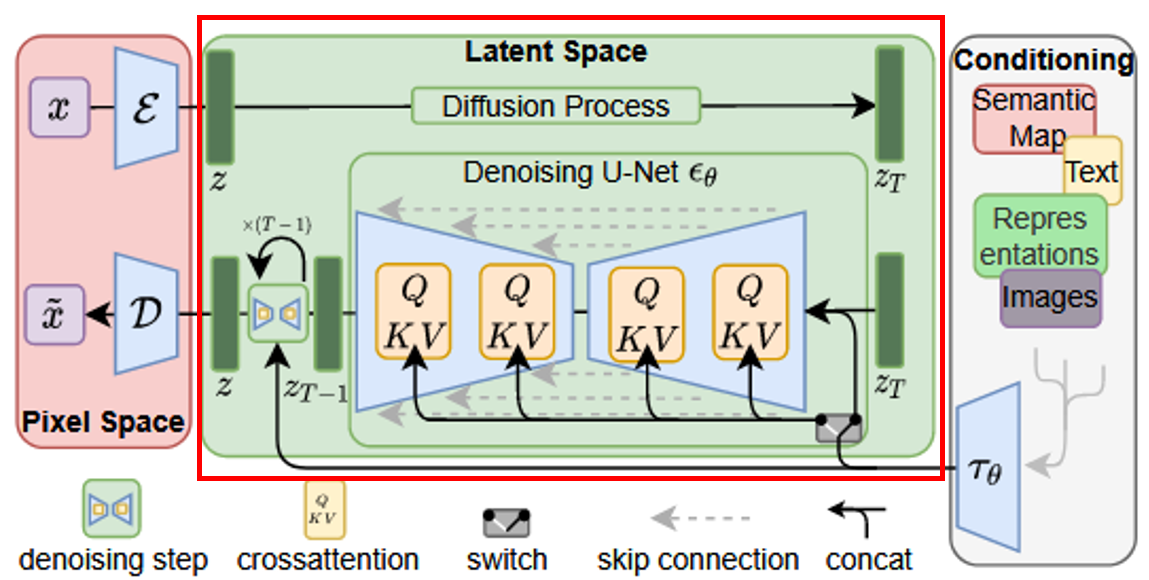
原先U-Net结构中是siglehead attention,这里用了multi-head attention替代:
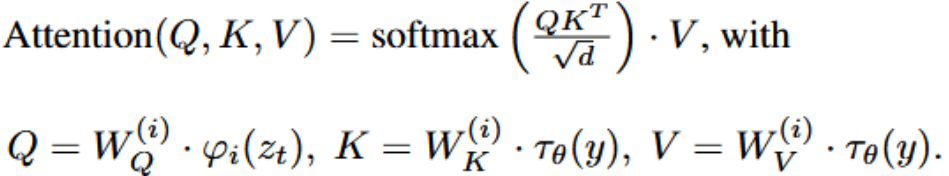
其中y可以是任何我们想要引入的condition,实验效果如下:


源码可以在 网址1 网址2中看一下,我目前是简单看了一下,还没有跑。
个人感悟
1、这个工作最核心的贡献点是提出了一种图像翻译工作的通用框架,如果能微调实现任意图像翻译工作,那么这项工作堪称划时代的意义,或许能比肩pix2pix GAN。后面我会在这方面进行尝试。
2、至于作者说的超分、计算资源的节约等等,前人后人都做过比较成功的探索,相比于通用图像框架来说,显得比较“卑微”。
3、作者的故事切入很牵强,主要说别人消耗的资源太多不环保,但是latent difusion models无疑也是大模型,就因为能减少模型使用次数+能迁移所以环保? emmm反正成果牛逼就行哈哈哈。
核心代码
1 | class LatentDiffusion(DDPM): |
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/11/27/Latent-Diffusion-Models-原理和代码/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!