

前言:上次做了户型图数据集调研,并构建了自己的户型图数据集,这次使用构建好的数据集训练自己的Diffusion Model
本次我训练了四个版本的Diffusion Model for Floor Plan datasets,分别是:
cubicasa5k-Simple-DM
cubicasa5k-Large-DM
RPLAN-DM
Myself-DM(自己从网上爬取的数据集)
训练伊始的踩坑
ok,我的训练从入门快进到了入土,看一下提示出来的信息吧:
1 | 2023-11-29 18:10:57 LAPTOP-56LC5HQ1 __main__[684] INFO [None]: Input params: Namespace(act='gelu', batch_size=2, cfg_scale=3, conditional=False, dataset_path='../datasets/RPLAN', distributed=False, epochs=300, fp16=False, image_size=64, load_model_dir='', lr=0.0003, lr_func='linear', main_gpu=0, num_classes=1, num_vis=-1, num_workers=0, optim='adamw', result_path='../results', resume=False, run_name='RPLAN_model', sample='ddim', save_model_interval=True, seed=0, start_epoch=-1, start_model_interval=-1, vis=True, world_size=2) |

我手里就一张4070,只有可怜的8GB显存,batch_size调大点,显存直接爆炸,batch_size调小点,训练一轮竟然要40分钟!!而且我之前也没有训练diffusion model的经验,也不知道大概训练多少轮会收敛,以300轮为例,要8天才能训练完,难顶。
主要是也没有做实验室的工作,用实验室的服务器说不过去,现在只能找一些其他的算力资源了,之前白嫖colab,但是这个靠运气,而且白嫖到的卡也一般,和我这4070半斤八两,那就只能租服务器了,正好也记录一下远程服务器的相关配置啥的。
租带卡服务器用于自己的训练
我选择的租服务器平台是: 服务器平台
当前要花钱的,其实也还好,我比较推荐3090,显存大,单精双精都好,性价比挺高的。
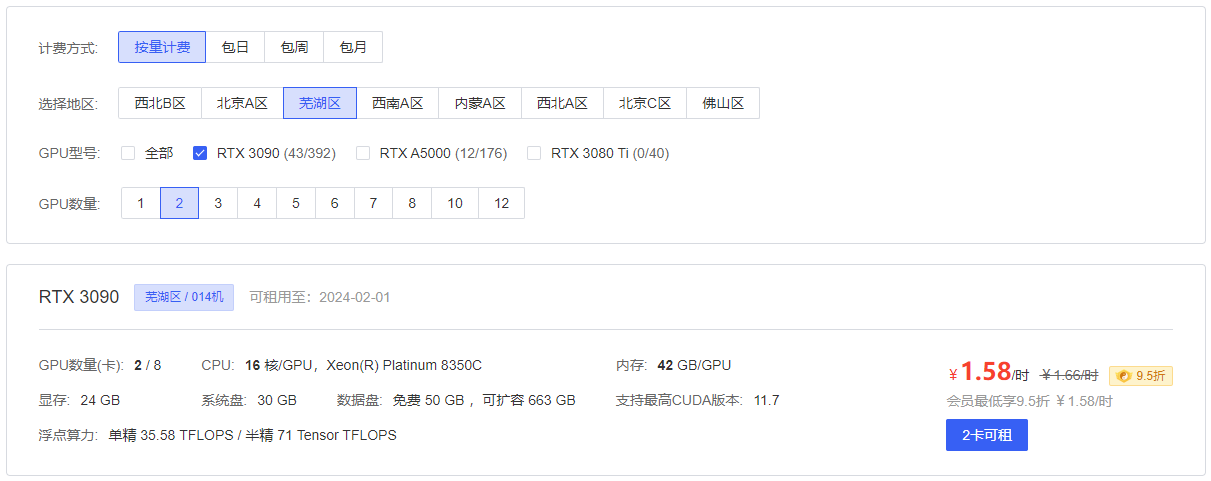
我这里打算租一台两张3090的服务器
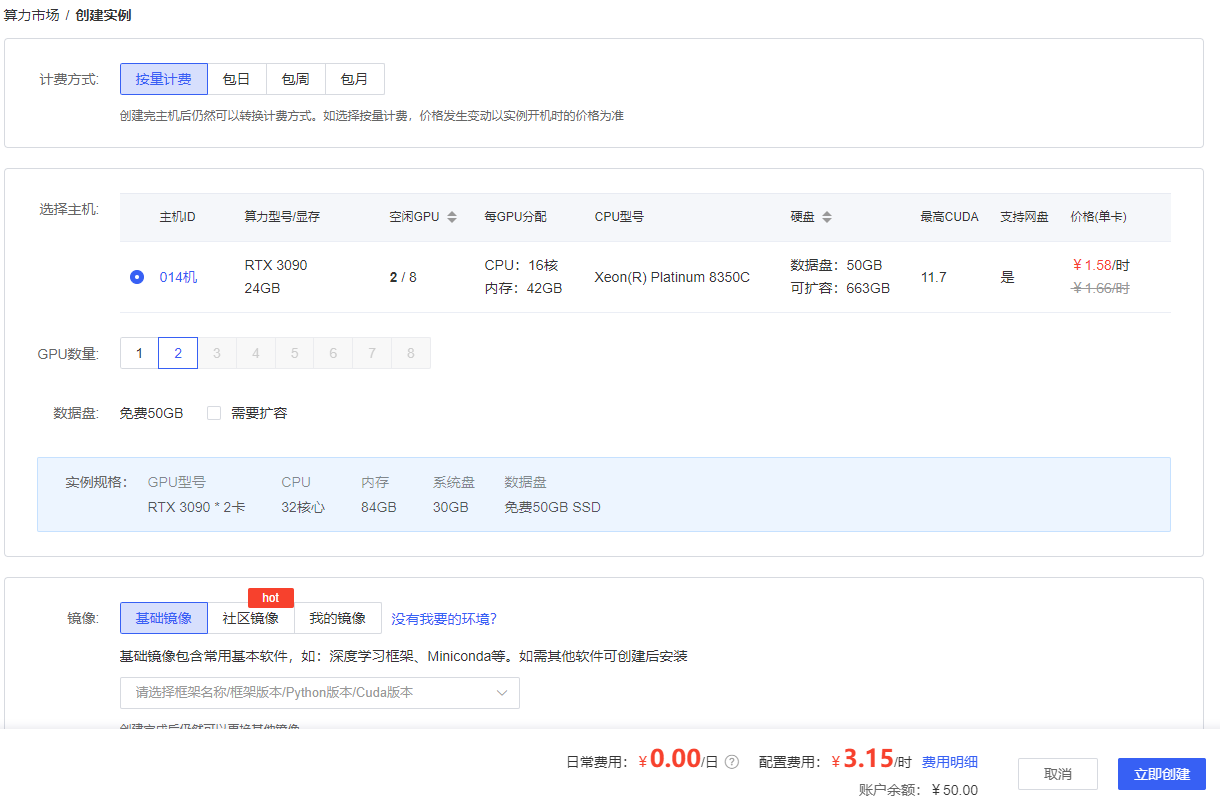
3块多一个小时,勉强可以接受~
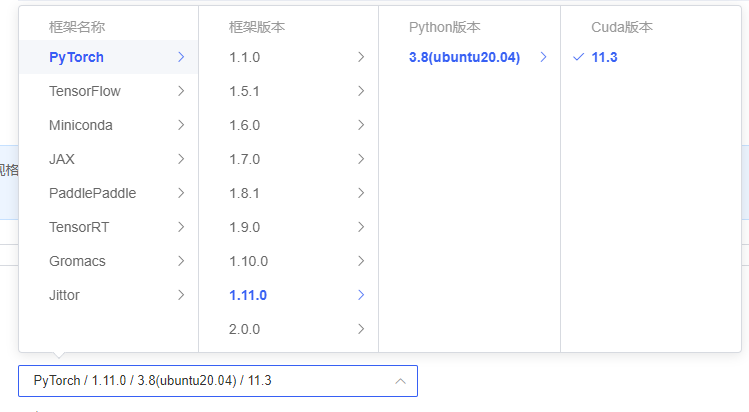
镜像建议用基础镜像,每台机器对cuda和pytorch的兼容程度不一样,注意选择。

ok,这样我们就创建好了
用pycharm连接远程服务器
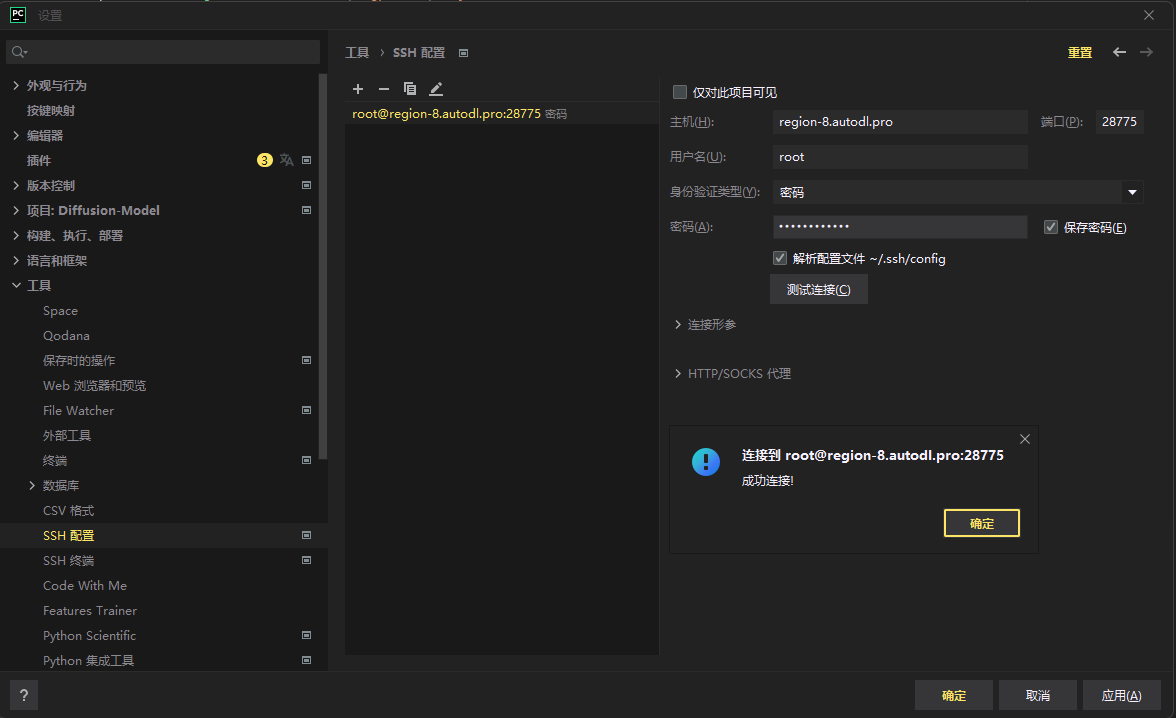
连接SSH
根据上面给出的SSH登陆填入pycharm中:
配置python解释器
服务器上后很多python环境,我们要选择我们想要的,现在的服务器一般都是miniconda
现在服务器终端中看一下python在哪
然后选取/root/miniconda3/bin/python复制到pycharm中:
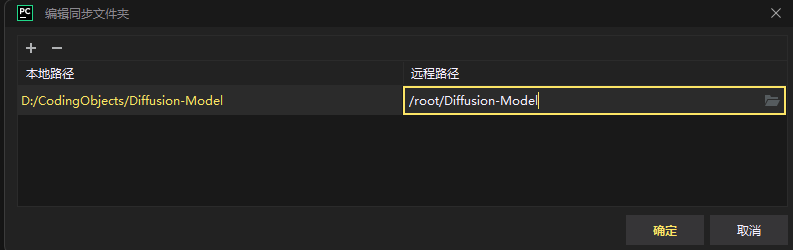
同步文件夹
这里要把当前本地的工程文件上传到服务器中,最后自己命名一个文件夹
之后我们就等本地文件上传至服务器中(这个时间还是挺长的)

ok,经过漫长的等待,在服务器里已经有这个项目了:
很少能打这么富裕的仗,记录一下吧~
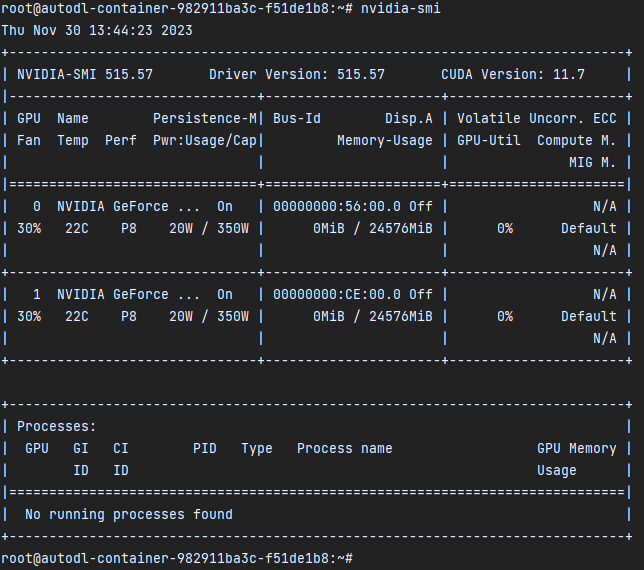

这个提示是显存不够(看来batch_zise=16对于2张3090还是太暴力了,那么最直接的办法是batch_size调小一点)
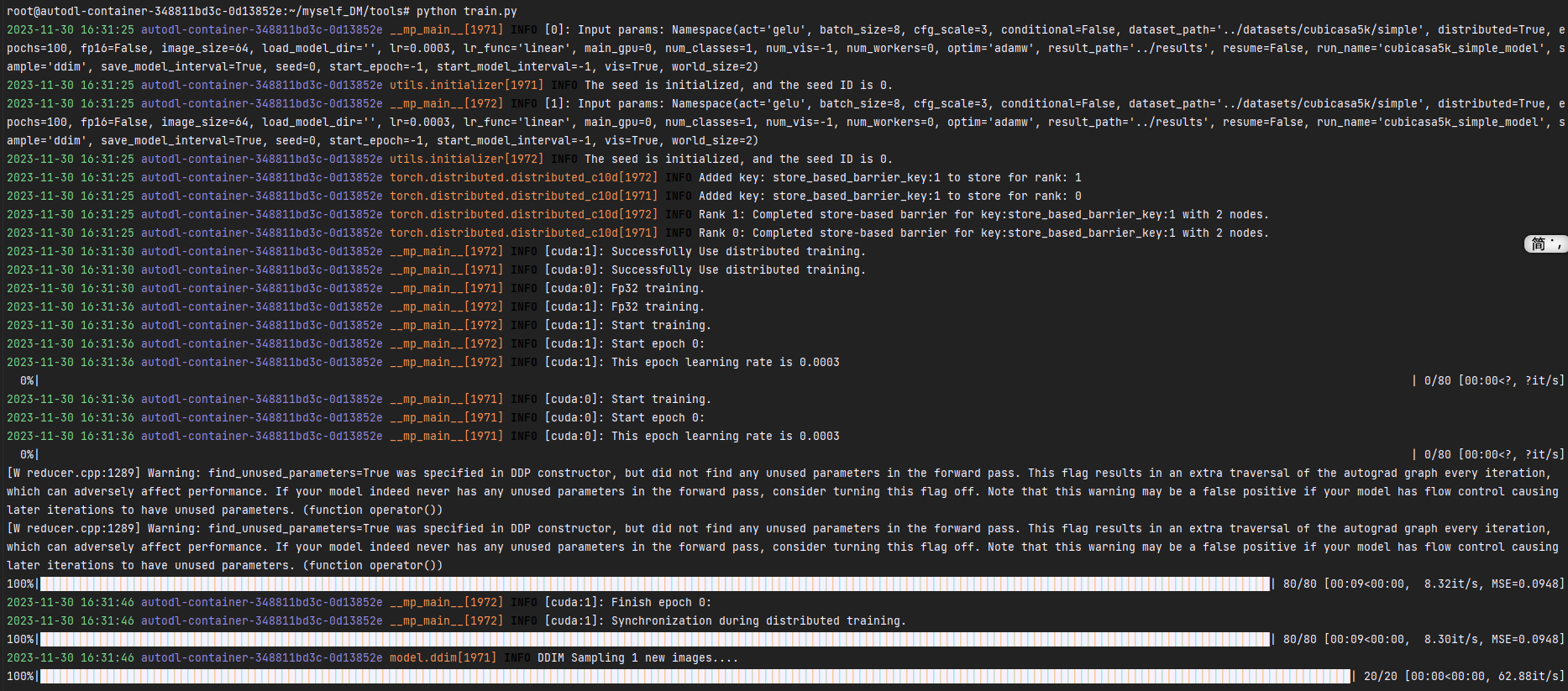
谢天谢地,终于训起来了,该说不说,这富裕仗打的就是爽,一个epoch就十几秒!以后高低得整个10张4090的服务器吧~
数据集预处理
上次已经找好数据集了,但是毕竟是在别的任务上的数据集,一般又以下几个问题:
- 分辨率过大(RPLAN数据集是256*256的,cubicasa5k是完全不规则的)
- 数据格式不统一
- 标注的问题
标注问题上次已经解决过了,现在我们手头的是纯图片数据集,这也正是image-to-image的Diffusion Model所需要的,那么下买面就来解决分辨率的问题,这个问题一开始我没有意识到,所以在我最开始的训练是即使把batch_size调到最小、选用fp16后,显存依旧会爆炸,在和老师沟通后了解到Diffusion Model一般是用64*64的,过大的分辨率会先下采样,那么下面就分数据集来说明对其的预处理。
RPLAN数据集
这个数据集本身就是纯图数据集,主要是本身为256*256的,那么我们只需要resize一下就行
1 | import os |
这样就可以直接用了
cubicasa5k数据集
这个数据集比较麻烦,它的文件结构是这样的:
1 | ├── cubicasa5k |
我大概看了一下,其中的png格式的数据质量不一,colorful里的是彩色的,high_quality是黑白的,high_quality_architectural是较为复杂的,而且其中有的是标准的户型图,有的是手稿,所以我决定提取其中model.svg数据,这个矢量化数据还是比较标准的。
提取model.svg数据
把每个文件夹下的model.svg数据提取出来,放在一个文件夹中,然后转成png格式。
1 | import os |
转成png格式:
1 | import cairosvg |
再把所有图片都resize成64*64的大小:
1 | from PIL import Image |
为了比较不同情况下的数据集训练出来的结果,我把cubicasa5k分为了cubicasa5k-simple和cubicasa5k-large两个版本
1 | ├── cubicasa5k-simple |
ok,终于处理完了数据集,开始训练把~
对cubicasa5k的训练
刚才分为了两个版本,那我们分开训练
对cubicasa5k-simple的训练
不太清楚要训练多少轮,因为不同的数据集不同的轮次训练出来的效果是不一样的,没有一个固定的标准。
我这里训练了600个epoch,其实从训练中反馈的信息来看,训练到200轮的时候就已经收敛的差不多了:
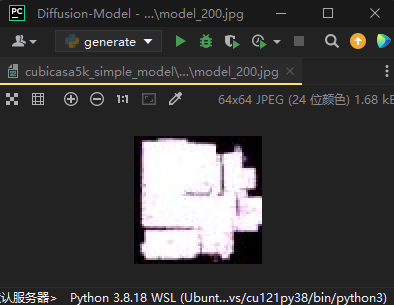
那么最终训练完600轮后效果如下:
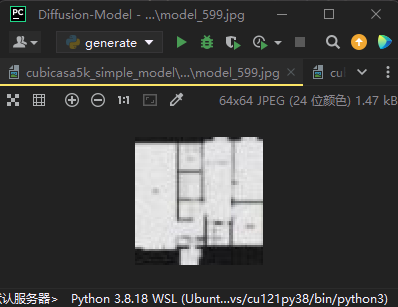
对cubicasa5k-large的训练
cubicasa5k-large和cubicasa5k-simple的区别就是,cubicasa5k-large包含了更多复杂结构户型图数据,所以训练起来是要比simple版本难得,实际实验看出,在训练到200轮的时候,依旧部分收敛,但是还是存在很明显的高斯噪声分布:
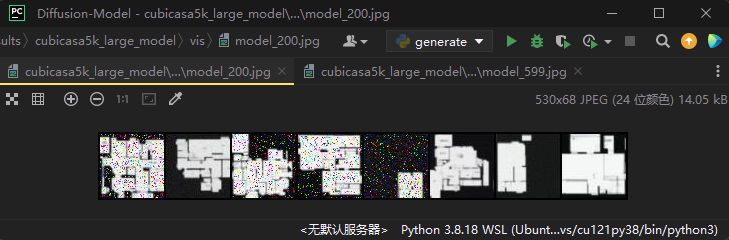
最终训练完600轮的效果如下:
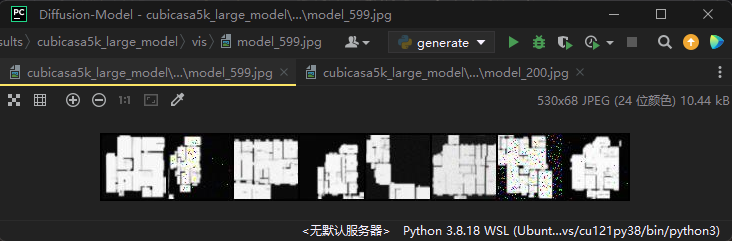
可以看出,大部分是采样的比较好的,偶尔有一两个噪声分布比较明显。
对RPLAN的训练
RPLAN这个数据集比较大,有八万多张图片,所以训练起来就比较难,**在 2*3090(24G) GPU的服务器上,batchsize=8,训练一轮要9分40秒,整体的训练代价是比较大的,所以这里我总共训练了200轮**。
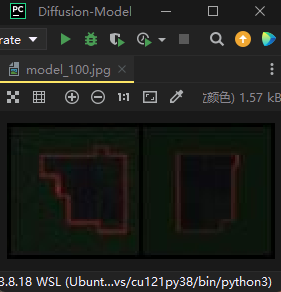
第100轮时的效果:
第200轮时的效果:
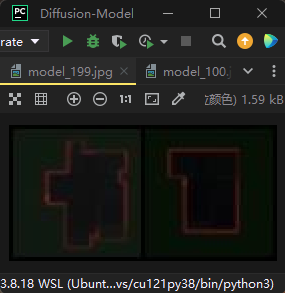
可以看到收敛的速度还是比较快的,因为这个数据比较简单,没有太复杂分布。
再者说,我感觉这个数据集主要的任务是:Layout Generation,可能用在这次设计中有点不太合适。
对自己构建的数据集进行训练
之前也提到了,我从二手房网站上爬了一些数据,构建了自己的数据集,经过人工清洗之后,可用的数据量大概3000多张:
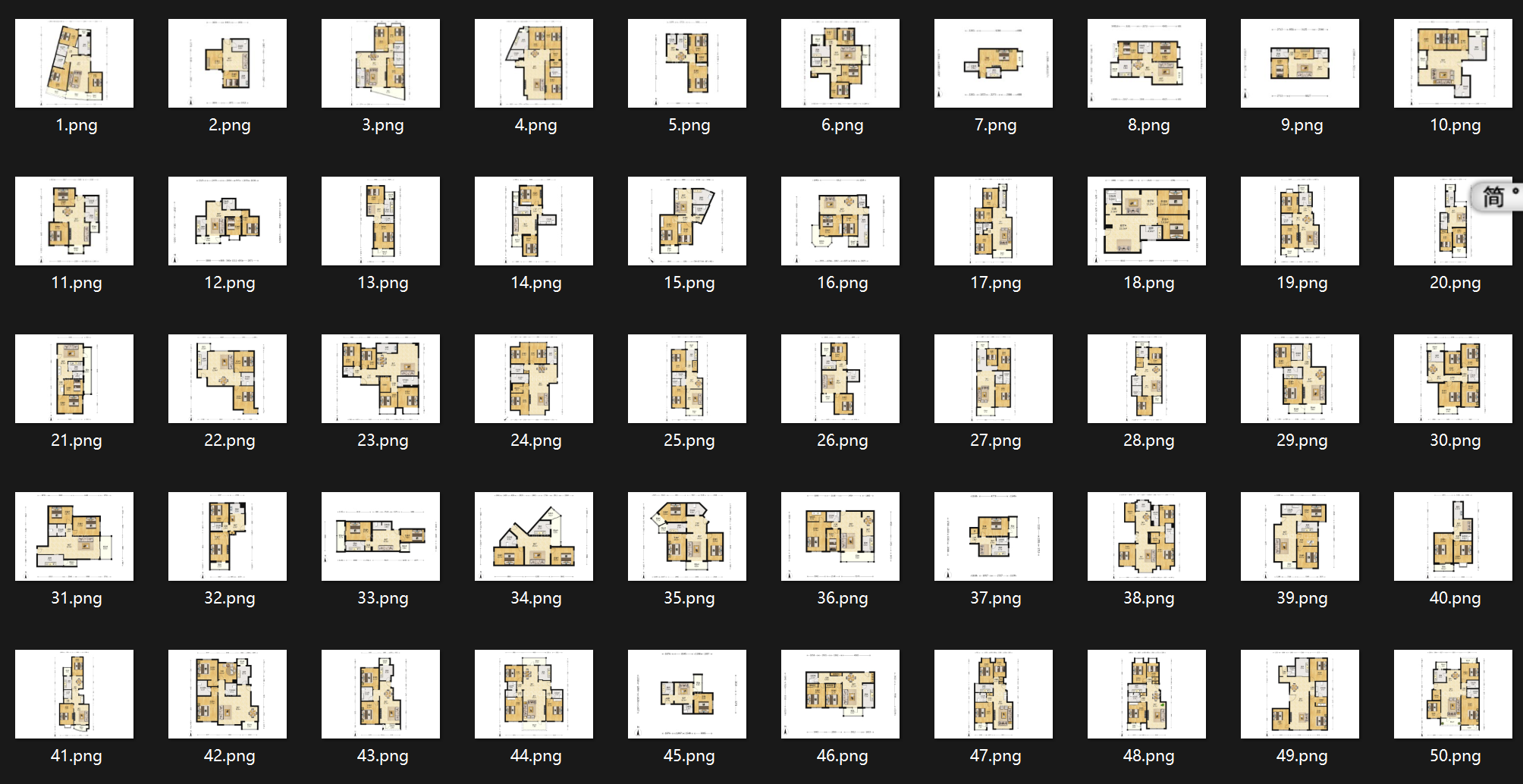
针对这个数据集,我也训练了600轮,看看效果吧:
200轮时效果:
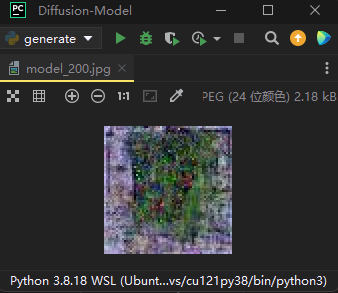
可以看到由于色彩较多,原始数据集的分布比较复杂,所以200轮的采样结果不是很理想,这里出现绿色是因为有些户型图数据中有草坪:

所以说针对这个数据集,多训练几轮是很有必要的,600轮的情况如下:
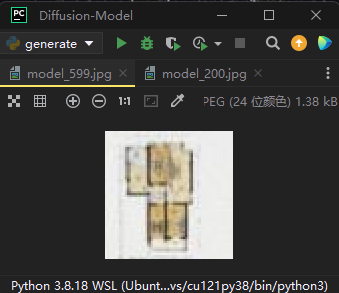
可以看出,600轮的时候就差不多了,由于实验室还有其他的工作要做,所以这次的训练就到此为止了。
测试
对cubicasa5k-Simple-DM的测试
对应参数调好:
生成指令:

输出结果:
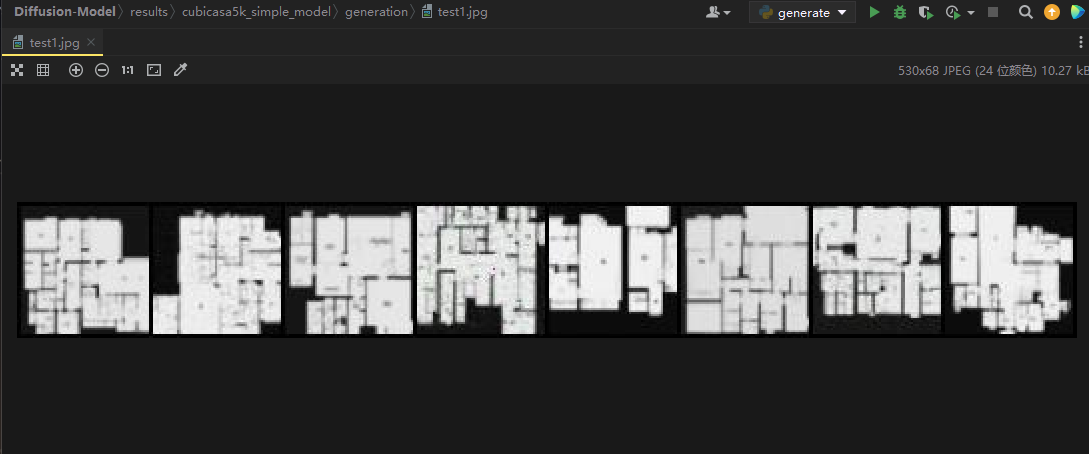
还是比较ok的
对cubicasa5k-Large-DM的测试
对应参数调好:
生成指令:
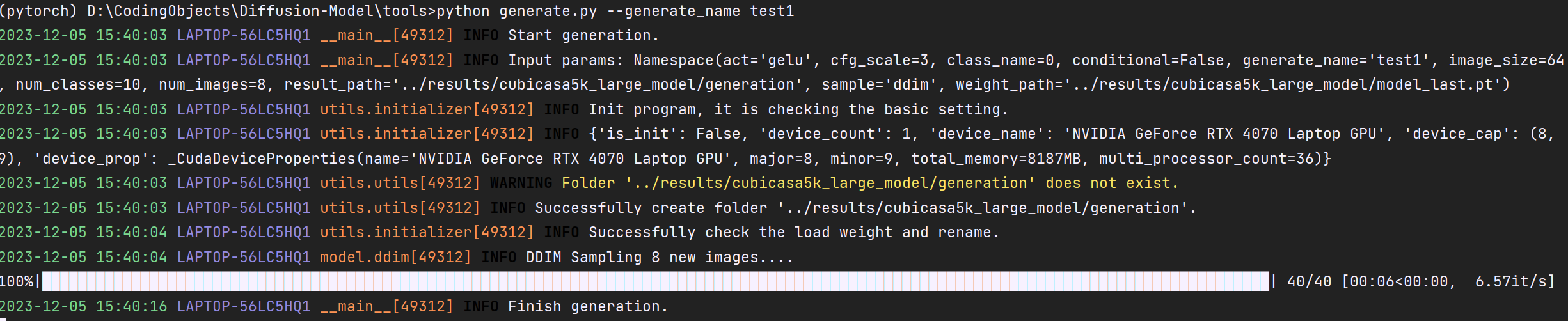
输出结果:
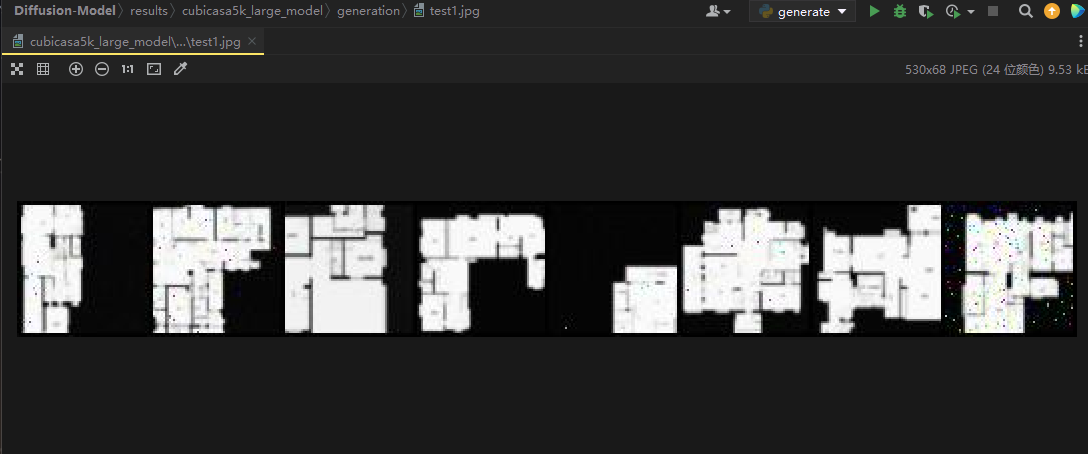
也算凑合
对RPLAN-DM的测试
对应参数调好:
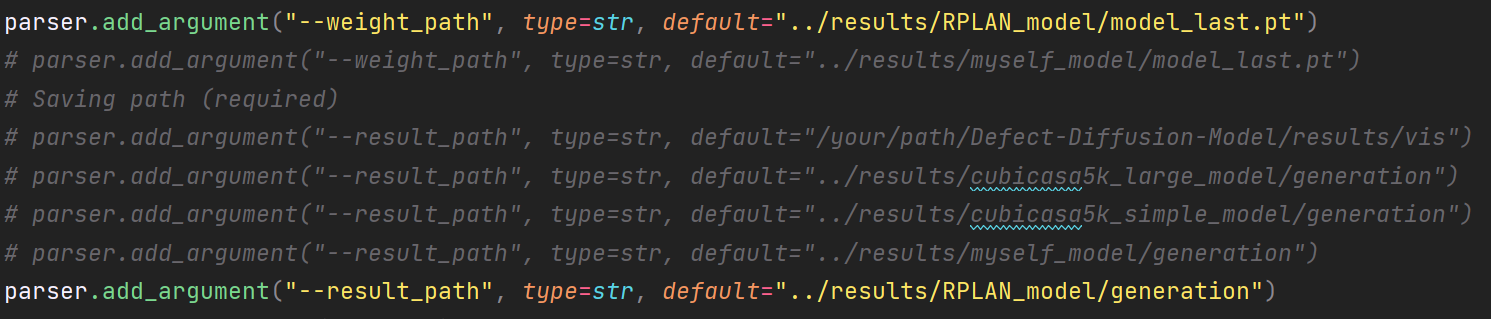
生成指令:

输出结果:
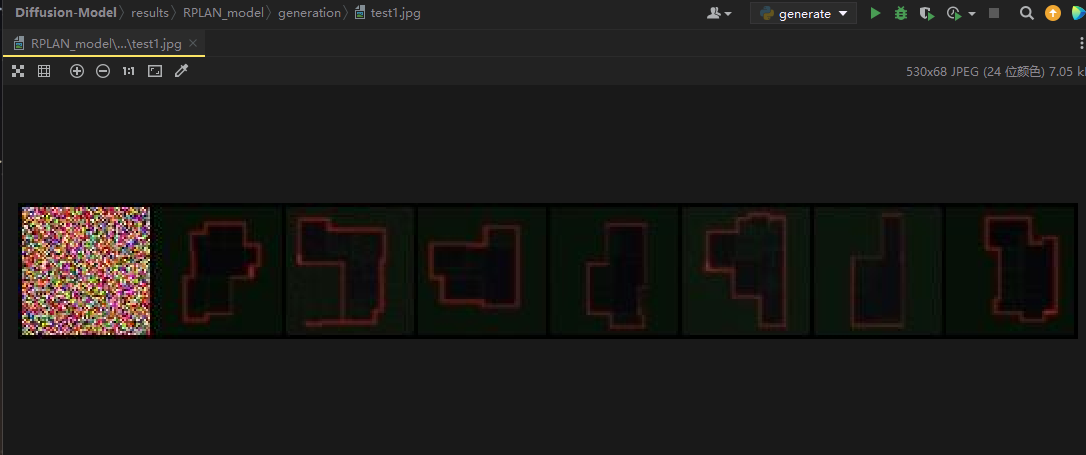
有一张崩了,剩下还好
对Myself-DM的测试
对应参数调好:

生成指令:
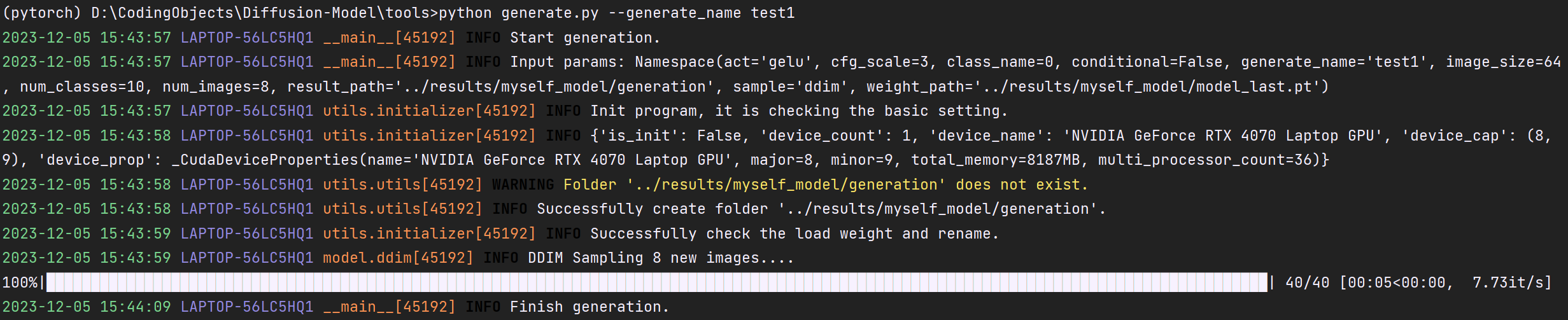
输出结果:
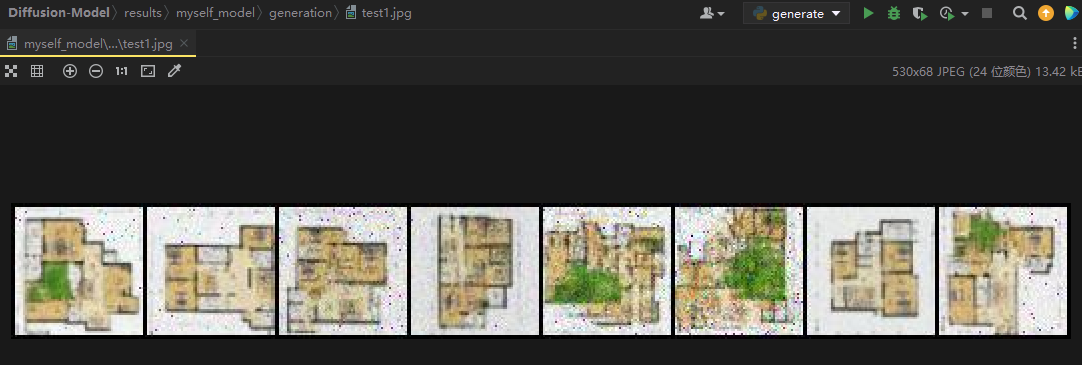
ok,可以看到也能生成对应的图像,只不过噪声比较多,后续有机会再补上剩下的训练吧。
总结
本次我训练了四个版本的Diffusion Model for Floor Plan datasets,分别是:
- cubicasa5k-Simple-DM
- cubicasa5k-Large-DM
- RPLAN-DM
- Myself-DM(自己从网上爬取的数据集)
后续该设计有新的实现也会同步更新,在设计验收后,我会将代码上传github。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/11/28/训练自己的户型图扩散模型/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!