

前言:精读论文:The Chosen One: Consistent Characters in Text-to-Image Diffusion Models,该论文与2023-11-30日上传至arXiv上,该工作由Google Research主导,主要关注的点在于多轮图像生成的角色一致性问题。这篇文章的代码还没有开源,但是作者建立的github仓库已经有1.2K的follow了
github仓库 [未开源]
1 对论文的初印象
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
The Chosen One:文本到图像扩散模型中的一致字符
看到题目标题以为是直接输入prompts就可以生成一致角色的,其实并不是,其实是通过一些小trick,变相的实现了这样的效果,对基础模型的细节也没有做特别大的改变,总体来看还是有局限性的。
2 Motivation
文本到图像生成模型难以生成一致的角色。
目前的方法:
- 依赖于目标字符的多个预先存在的图像
- 涉及劳动密集型的手动过程
原文:Despite the increasingly impressive abilities of text-toimage generative models, these models struggle with such consistent generation, a shortcoming that we aim to rectify in this work.
This work:
- 提出了一种完全自动化的解决方案,用于一致的角色生成,唯一的输入是文本prompts。
- 引入了一个迭代过程,在每个阶段,识别一组具有相似身份的连贯图像,并从该集合中提取更一致的身份。
基于这样一个假设:
- 对于某个prompt,一个足够大的生成图像集中会包含具有共享特征的图像组。
- 给定这样一个簇,提取其中的“common ground”。
- 重复这样一个过程,可以增加生成图像的一致性,同时仍然符合原始的prompt。
核心的处理思路:
- 1:根据文本prompt生成一组图像
- 2:使用预训练好的特征提取器(feature extractor)将它们embed到Euclidean space
- 3:对这些embedding进行聚类,选择the most cohesive的簇。
- 4:将这个簇作为生成模型的下一次输入,会生成一组一致性更像的图像集(同时描述输入的prompt)
- 5:重复这个过程直到收敛
贡献点:
- (1)将一致角色生成任务形式化
- (2)为这项任务提出了一种新颖的解决方案
- (3)除了user study之外,还定量和定性地评估方法,以证明其有效性。
3 Method
3.1 笼统阐述
一个T2I的模型 \(M_{\varTheta}\)(由 \(\varTheta\) 参数化,\(\varTheta\) 由一组模型权重 \(\theta\) 和一组自动以文本embedding \(\tau\) 组成 )
一个文本prompt \(p\)
需要找到一种表示形式 \(\varTheta \left( p \right)\) ,参数化模型 \(\varTheta \left( p \right)\) 能够在新的上下文中生成由 \(p\) 描述的角色一致性图像。
算法如下:

算法执行前提:
- 1:有一个由扩散模型M生成的由相同文本prompt驱动的足够大的图像集
- 2:这个图像集with different seeds,将反应生成的图像集的不均匀密度
我们希望找到一些具有共同特征的图像组,其中一组图像中的“common ground(共同点)”可以用于细化表示 \(\varTheta \left( p \right)\)。
3.2 Identity Clustering 身份集群
Step1:使用 \(M_{\varTheta}\) 开始每次迭代(使用 \(\varTheta\) 进行参数化),生成 \(N\) 个图像集合,每个图像对应一个不同的随机种子。
Step2:使用特征提取器 \(F\),将每张图像 embed 到 high-dimensional semantic embedding space(高维语义嵌入空间)。形成一组 embeddings : \[ S=\bigcup_N{F\left( M_{\varTheta}\left( p \right) \right)} \] > 实验中,用DINOv2作为特征提取器 \(F\)
公式解释:
- \(F\) 是特征提取器,用于将图像嵌入到高维语义嵌入空间中。
- 对于每张生成的图像 \(M_{\varTheta}(p)\),其中 \(p\) 是随机种子,使用特征提取器 \(F\) 得到该图像的 embedding 。
- 这样就得到了一组嵌入集合 \(S\),其中每个元素是一个图像的嵌入。这个嵌入过程通过公式表示为:
\[ S = \bigcup_N{F\left( M_{\varTheta}\left( p \right) \right)} \] 其中 \(\bigcup_N\) 表示将 \(N\) 个集合合并在一起,\(F\left( M_{\varTheta}\left( p \right) \right)\) 表示将生成的图像 \(M_{\varTheta}(p)\) 的嵌入。
Step3:使用K-Means++算法,根据embedding space中embedding的余弦相似度进行聚类。通过删除所有大小地狱预定阈值 \(d_{\min -c}\) 的簇(这么做的原因:之前工作表明个性化算法容易在小数据集上过度拟合)
Step4:剩下的簇中,选择最内聚的那个簇作为 identity extraction阶段的输入,如下图:
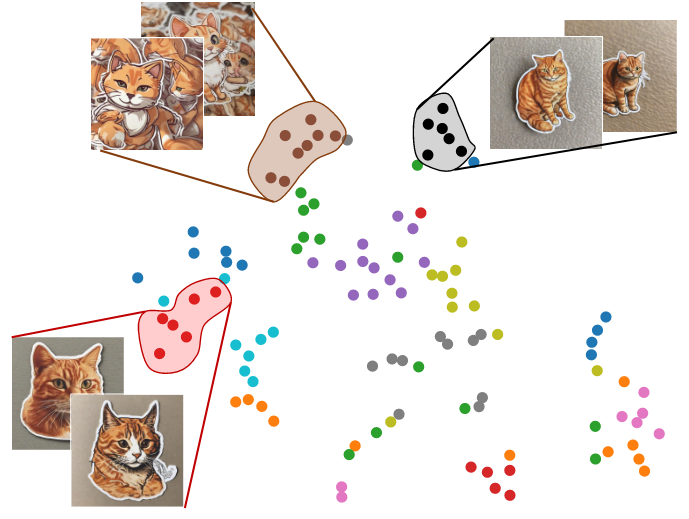
(其中黑色簇是最具内聚性的)
如何定义簇的内聚性呢?
将簇\(c\)的内聚性定义为\(c\)的成员与其质心\(c_{cen}\)之间的平均距离: \[ cohesion\left( c \right) =\frac{1}{\left| c \right|}\sum_{e\in c}{\lVert e-c_{cen} \rVert ^2} \] > 实验具体配置: > > 特征提取器:DINOv2 > > DINOv2嵌入空间中的高维嵌入使用t-SNE投影到2D中,根据他们的K-Means++簇进行着色,黑色簇是最紧的。
3.3 Identity Extraction 身份提取
根据当前迭代中生成的图像集的多样性,最内聚的聚类可能仍然表现出不一致的身份,如下图所示:
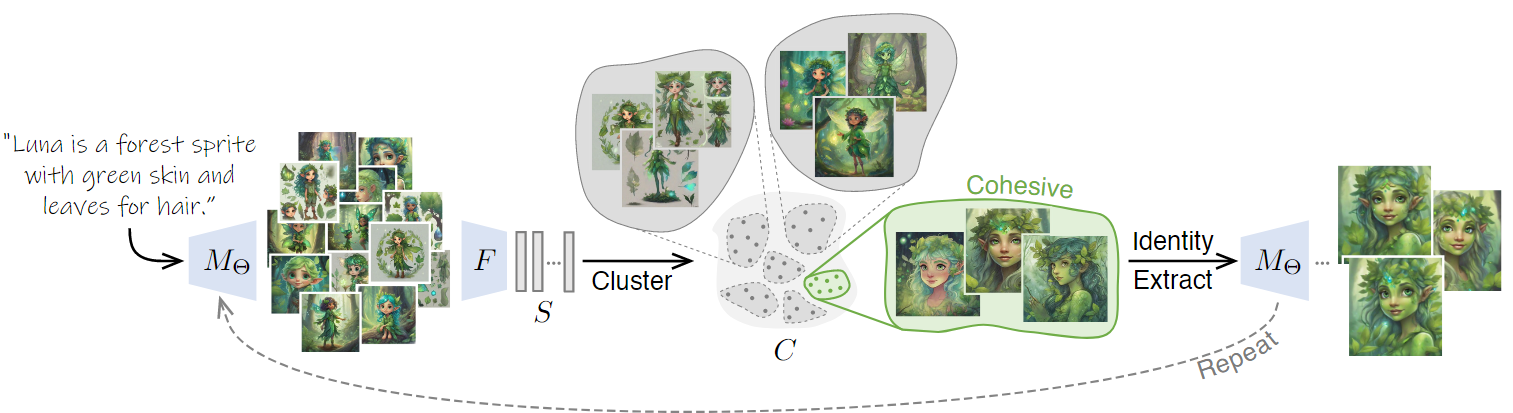 因此,\(\varTheta\)并没有适合一致性的生成,应该通过在聚类好的图像\(c_{cohesive}\)上进一步训练来改进它,以提取更一致的角色。
因此,\(\varTheta\)并没有适合一致性的生成,应该通过在聚类好的图像\(c_{cohesive}\)上进一步训练来改进它,以提取更一致的角色。
这种进一步细化是使用 T2I 的个性化方法进行的,其目的是从已经描述一致身份的几张图像的给定集合中提取角色。(当我们将它们应用于一组不完全一致的图像时,这些图像是根据它们彼此的语义相似性来选择的,这一事实使这些方法能够从它们中提取出一个共同的身份。)
实验设置:
扩散模型:Stable iffusion XL(SDXL)
两个text encoder:CLIP 和 OpenCLIP
使用 Textual Inversion(文本反转)来添加一对信的文本token \(\tau\),两个text encoder各一个。
但是实验中发现这个parameter space is not expressive enough(参数空间不够表达),所以还需要LoRA来微调模型权重 \(\theta\)。
使用standard denoising loss(标准去噪损失): \[ \mathcal{L}_{rec}=\mathbb{E}_{x~c_{cohesive},z~E\left( x \right) ,\epsilon ~\mathcal{N}\left( 0,1 \right) ,t}\left[ \lVert \epsilon -\epsilon _{\varTheta \left( p \right)}\left( z_t,t \right) \rVert _{2}^{2} \right] \]
公式解释:
- \(c_{cohesive}\) :选择的聚类
- \(E\left(x\right)\) :SDXL的VAE编码器
- \(\epsilon\) :样本的噪声
- \(t\) :时间步长
- \(z_t\) :是time step \(t\)时的latent \(z\) 噪声
- 在 \(\varTheta =\left( \theta ,\tau \right)\) 上优化 \(\mathcal{L}_{rec}\) (即the union of the LoRA weights and the newly-added textual tokens.)
3.4 Convergence 收敛
注意一点,上述过程中每次迭代提取的representation \(\varTheta\) 是用于下一次迭代生成\(N\)个图像。
整个收敛过程并不是使用固定的迭代次数,而是会使用一个收敛标准:
- 每次迭代后,计算新生成图像的所有N个embedding之间的average pairwise Euclidean distance(平均成对欧几里德距离)
- 直到该距离小于预定的阈值\(d_{conv}\) 时停止。
- 最后,需要注意的是,这个方法是不确定的,即在相同的输入prompt \(p\)上,会产生不同的一致性角色。
4 Experiments
这个论文我是打算复现的,复现后更新。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/07/论文精读-The-Chosen-One-Consistent-Characters-in-Text-to-Image-Diffusion-Models/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!