

前言:精读论文:AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort,该论文与2023-11-23日上传至arXiv上,该工作由浙江大学提出,主要关注的点在于对一个文本故事进行可视化和多轮图像生成的一致性(包括角色与非角色)
[未开源]
1 对论文的初印象
AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort AutoStory:用最少的人力生成多样化的故事图像 标题给的很直白
2 前情提要
2.1 故事可视化
旨在生成一系列与文本中描述的故事相匹配的图像,要求生成的图像满足高质量、与文本描述一致以及角色身份的一致性。
2.2 现有的做法
现有的方法通过只考虑几个特定的角色和场景,或者要求用户提供每个图像的控制条件(如草图),大大简化了问题。然而,这些简化使得这些方法不能用于实际应用。
2.3 This Work
提出了一种自动化的故事可视化系统,该系统可以有效地生成多样化、高质量和一致的故事图像集,并将人类互动降至最低。
2.4 具体的做法(笼统)
利用大型语言模型的理解和规划能力进行布局规划(layout),然后利用大型文本到图像模型基于布局(layout)生成复杂的故事图像。
根据实验发现:
- 稀疏控制条件(spare control conditions,如边界框 bounding box)适用于布局规划
- 密集控制条件(dense control conditions,例如草图和关键点 sketches and keypoints)适用于生成高质量的图像内容。
为了两全其美,设计了一个密集条件生成模块(作为桥梁),将简单的边界框布局转换为草图或关键点控制条件,用于最终图像生成,这不仅提高了图像质量,还允许简单直观的用户交互。
We exploit few-shot parameter-efficient fine-tuning techniques for foundation models。
AutoStory结合定制的生成技术,通过只对每个角色的几个图像进行训练,同时将其推广到不同的角色、场景和风格,实现了身份一致性生成。
此外,这篇工作提出了一种简单而有效的方法来生成多视角一致的人物图像,消除了收集或绘制人物图像对人力的依赖。
具体来说,提出了一种 training-free 的身份一致性建模方法,将多个视图视为视频,and jointly generating the textures with temporal-aware attention。还通过利用视图条件下的3D先验图像翻译模型来提高生成的角色图像的多样性,而不影响身份一致性。
3 Method
目标
用最少的人力(最少的人工准备和交互)生成高质量、多样化且具有一致性的讲故事的图像。
PS:用来讲故事的图像是有很强的场景复杂性的。
总体想法
LLM的理解能力和planning能力 + T2I模型的生成能力。
总体pipeline如下所示
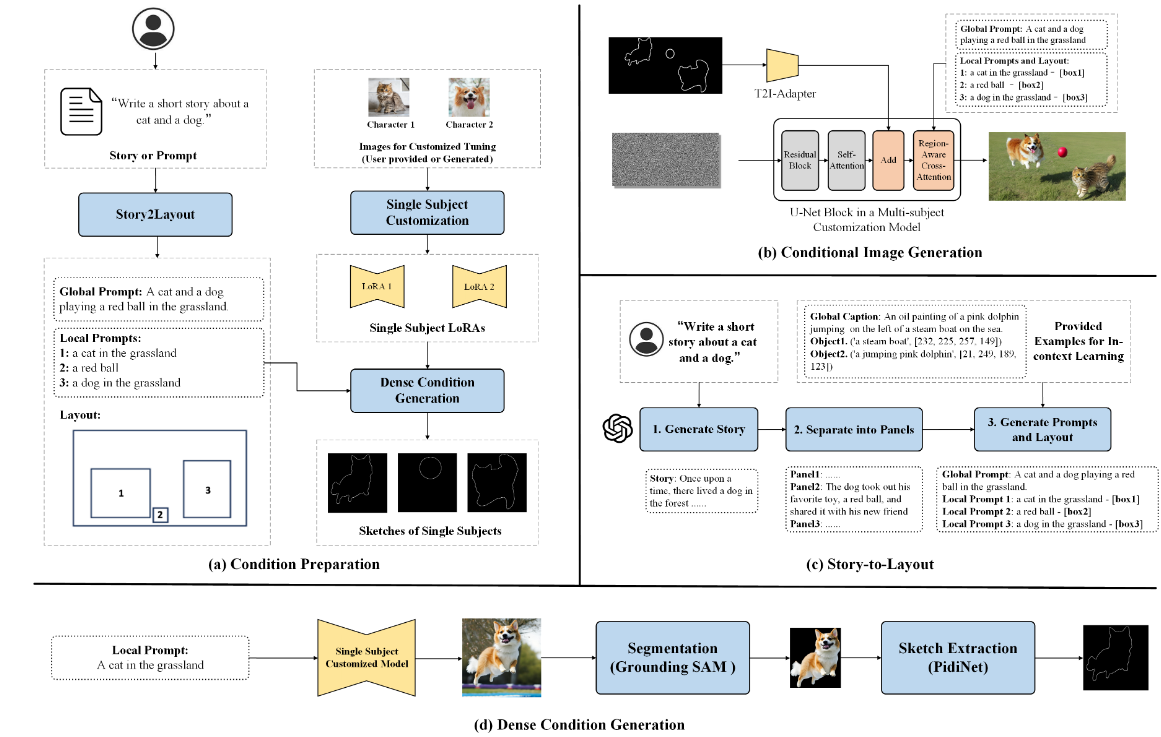 这个过程可以分为两个阶段:
这个过程可以分为两个阶段:
- 条件准备阶段(condition preparation)
- 条件图像生成阶段(condition image generation)
具体来说
- 首先利用LLM将文本故事描述转换为讲故事图像的layout。
- LLM生成的讲故事图像layout属于稀疏控制条件(spare control conditions),最好把其转换成密集控制条件(dense control conditions),针对这一点,也需要提出一个方法将稀疏的 bounding box 转换成密集的 control signals。
- 根据转换好的 layout 生成具有合理场景安排的故事图像。
- 最后再通过一种方法来提高生成图像的角色一致性。
总体来讲这样的方法只需要在少数图像上微调T2I模型,训练难度不大。
下面来一个一个步骤展开来说。
4 Text Story -> Layout Generation
这部分也分两个步骤:
- story pre-processing
- layout generation
4.1 Story Pre-processing
用户的输入可以是:
- 完整的故事 \(S\)
- 故事的简单描述 \(D\)
当输入的是故事的简单描述 \(D\)
时会使用LLM来生成特定的故事情节,即: \[
S=LLM\left( F_{D2S},D \right)
\] 过程如图所示:
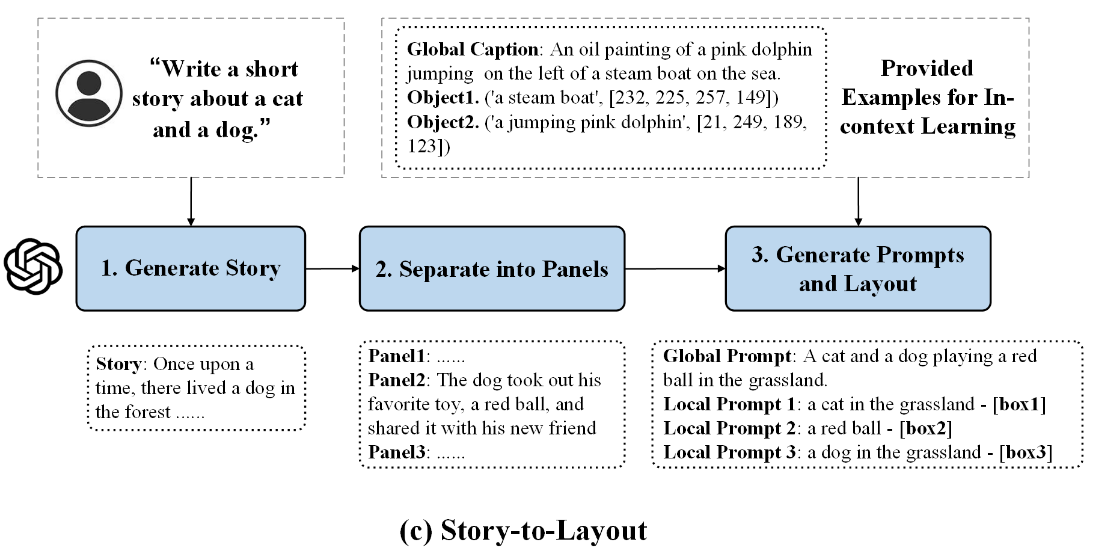 \(F_{D2S}\) 是帮助 LLM 生成故事的
instruction
\(F_{D2S}\) 是帮助 LLM 生成故事的
instruction
举个例子,在获取到故事 \(S\) 之后,要求LLM将故事分成 \(K\) panels,每个 panel 对应于一个图像(就很像之前的[IMG] token): \[ \left[ P_1,P_2,...,P_K \right] =LLM\left( F_{S2P},S,K \right) \] \(F_{S2P}\) 是指导模型根据故事生成 panels 的 instruction ,\(P_i\) 是文本描述的第 \(i\) 个 panel 。
至此,就完成了故事的预处理。
4.2 Layout Generation
将故事划分为 panels 之后,利用 LLM 从每个 panel 中提取 scene layout : \[ \left[ \sigma _1,\sigma _2,...,\sigma _K \right] =LLM\left( F_{P2L},\left[ P_1,P_2,...,P_K \right] \right) \] - \(F_{P2L}\)是指导模型根据 panel 生成 layout 的 instruction, - \(\sigma _i\) 是第 \(i\) 个 panel 的 scene layout,which consists of a global prompt \(p_{i}^{global}\) and several local prompts with corresponding localized bounding boxes:
\[ \sigma _i=\left\{ p_{i}^{global},\left( p_{i1}^{local},b_{i1} \right) ,\left( p_{i2}^{local},b_{i2} \right) ,...,\left( p_{ik_i}^{local},b_{ik_i} \right) \right\} \] - \(k_i\) is the number of local prompts in the i-th story image - \(p_{ij}^{local}\) 和 \(b_{ij}^{local}\) are the j-th local prompt and bounding box in the i-th story image。 - global prompt 描述整个故事图像的全局上下文 - local prompt 则侧重于单个对象的细节这种设计通过将故事图像生成的复杂性解耦为多个简单任务,帮助我们显著提高图像生成的质量。
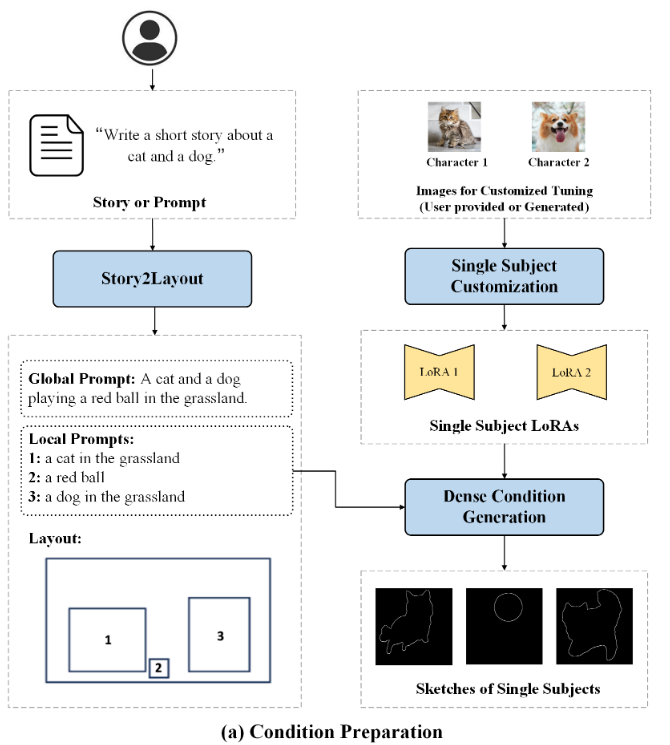
5 Dense Condition Generation 密集条件生成

5.1 Motivation
之前已经说过了,稀疏的 bounding box 很难生成高质量的图片,也有可能造成图像于 layout 不匹配的情况。
造成这些情况的原因主要是 bounding box 所提供的信息有限,因此需要引入 dense sketch or keypoint 作为guidances,因此在刚才生成的 layout 的基础上,引入一个 dense condition 生成模块。
5.2 Subject Generation
首先根据 local prompts 逐个生成 individual objects
这个过程可以表示为:\(I_{ij}=DM\left( p_{ij}^{local} \right) ,j=1,2,...,k_i\)
\(I_{ij}\) 表示第\(i\)个 panel 中的第 \(j\) 个 subject,由于单个对象生成 prompt 的简单性,生成过程相对容易,因此能够获得高质量的 single-object 生成结果。
5.3 Extracting Per-subject Dense Condition
- 在获取到single-object的生成结果后,使用open-vocabulary object detection方法(Grounding-DINO),对local prompt描述的对象进行定位,并且获得 localization box \(b_{ij}^{\det}\)。
- 之后,使用 SAM 来获得对象的 segementation mask \(m_{ij}\)(\(b_{ij}^{\det}\)作为 SAM 的 prompt)。
- 在 T2I Adapter之后,使用 PidiNet 来获得 the outer edges of the mask(这个可以被用作可控图像生成的dense sketch)(对于人类角色,也可以使用HRNet来获取人类姿态关节点作为dense conditions)
5.4 Composing Dense Conditions
最后,将前面得到的single-object的dense control condition粘贴到layout中对应的corresponding bounding box中,以获得整个图像的dense condition。
6 Controllable Storytelling Image Generation
可控的故事图像生成
这部分的工作:通过引入额外的控制信号来提高图像生成的质量。
6.1 Sparse Layout Control(稀疏layout control)
之前通过 LLM 获得了故事图像的总体 layout,下买就按照 layout 生成故事图像的详细内容。
选择在 Mix-of-Show 中的区域采样方法,因为这个方法不引入额外的模型参数/优化过程。(下面具体来说这个过程)
在cross-attention中,the feature inside the box \(b_{ij}\) 被替换成: \[ Attn\left( W^Qz_{ij},W^KE\left( p_{ij}^{local} \right) ,W^VE\left( p_{i}^{local} \right) \right) \] 通过这种方式,我们强制每个box中的image latent feature 聚焦在相应的local object上,因此生成的图像可以确认布局也可以避免对象之间的属性混淆。
整个基于global prompt和 sparse bounding box layout的生成过程可以写成: \[ DM\left( p_{i}^{global};\sigma _i \right) \] 当然以上的过程都是基于稀疏layout来做的,和之前工作的做法没什么不同,下面的才是核心。
6.2 Dense Control
上面那种方法生成的图像质量难免会差一点(之前也说过了),那么为了进一步提升图像质量,通过之前生成的dense condition来生成图像。
具体来说,我们将dense control signals注入到一个轻量级的T2I-Adapter,conditional generation过程可以表示为: \[ DM\left( p_{i}^{global};\sigma _i,\left\{ A,C_i \right\} \right) \] - \(C_i\) 是第\(i\)个story image的dense condition - \(A\) 是用于dense control的T2I-Adapter的型号
PS:这里使用的dense condition都是自动生成的,避免了之前工作中人工绘制草图的繁琐过程。
6.3 Identity Preservation
Identity Preservation过程挺重要的,这里借助Mix-of-Show中的思想。
给一个subject几个图像,用ED-LoRA对每个subject微调权重,以捕捉详细的subject特征。
使用梯度融合(gradient fusion)对单个角色的多个ED-LoRA进行合并,to guarantee the identity of all characters in the story。
融合后的LoRA权重表示为 \(\varDelta W\), 那么最终的生成过程可以写成: \[ DM\left( p_{i}^{global};\sigma _i,\left\{ A,C_i \right\} ,\varDelta W \right) \]
7 Eliminating Character-wise Data Collection
这部分主要对一致性角色生成进行讨论。
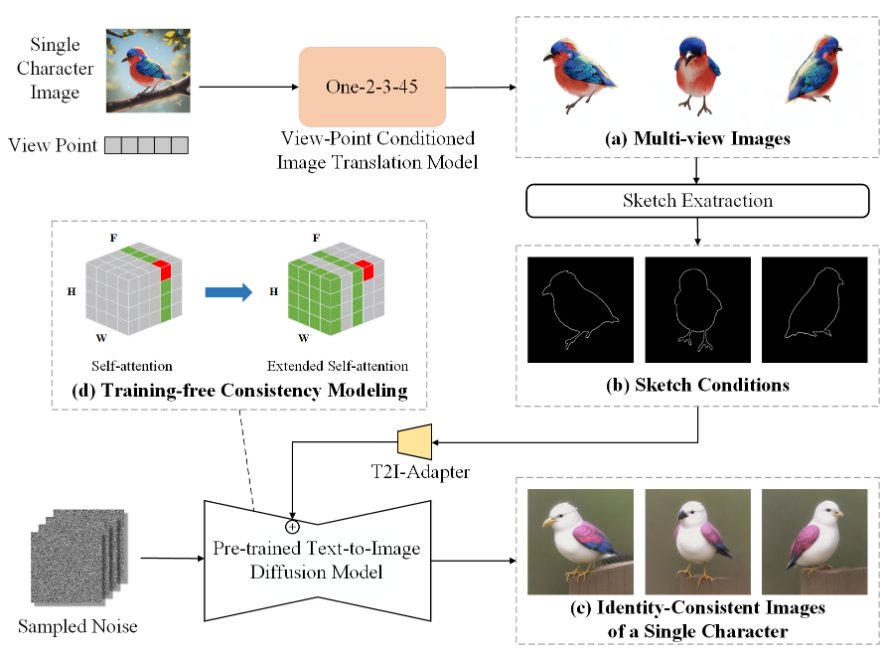
7.1 The Requirement of Character Data(对角色数据的要求)
To train a customized model of a character in a story,需要几个角色的图像来进行模型微调(可以写成 \(\left\{ I_{i}^{sub} \right\} ,i=1,2,...,n\),n是图像的数量)
为了获得针对单个角色的有效定制模型,训练数据需要满足:
- 身份一致性,训练图像的角色的texture和structure应该一致。
- 多样性,训练数据应该有所不同,例如在viewpoints,来避免模型过拟合。
7.2 Identity Consistency (身份一致性)
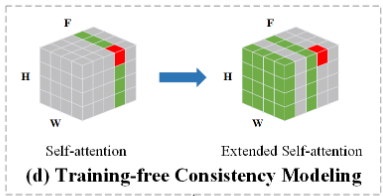
将单个角色的多个图像视为视频中的不同帧,并使用扩散模型同时生成它们,在这个过程中,DM中的self-attention要被扩展到其它”视频帧“,来增强图像之间的依赖性,以获得角色一致性的生成结果。
在self-attention中,让每个帧中的latent features关注前一帧和第一帧中的特征,来建立依赖关系,这个过程可以表示为: \[ Attn\left( W^Qz_i,W^K\left[ z_0,z_{i-1} \right] ,W^V\left[ z_0,z_{i-1} \right] \right) \] - \(z_i\) 是当前帧的latent feature,\(z_0\) 和 \(z_{i-1}\) 是第一帧和前一帧的latent feature。
- [·,·]是串联运算(concatenation operation)
7.3 Diversity(多样性)
上面的方法可以保证生成图像的角色一致性,但是每次生成出来的图像的多样性是不足的。
因此在不同帧中注入various conditions,来增强生成的角色多样性。
为了获得这些多样但角色一致的条件:
- 首先通过 \(I_{i}^{cond}=DM\left( p_{i}^{sub} \right)\) 生成一张图像(\(p_{i}^{sub}\) 是LLM生成的角色的描述)
- 使用训练好的view-point conditioned image translation model从不同的viewpoints获得角色的图像。

最后,提取这些图像的sketches或keypoints作为控制条件。
具体来说,对于第\(i\)个角色图像:
- Randomly generate the relative camera rotation \(R_{ij}\in \mathbb{R}^3\) 和 the relative translation \(T_{ij}\in \mathbb{R}^3\) of the desired viewpoint。
- 使用One-2-3-45 生成 desired viewpoints 中object的图像:
\[ I_{ij}^{cond}=f\left( T_{i}^{cond},R_{ij},T_{ij} \right) ,j=1,2,...,n \] 之后,从这些图像中提取非人类角色的sketches/人类角色的keypoints。
最后,在生成过程中使用T2I-Adapter将control guidance注入到相应帧的latent feature中。
为了进一步保证生成数据的质量,使用CLIP评分对生成的数据进行过滤,选择与文本描述一致的图像作为训练数据进行定制生成。
7.4 本节总结
在Eliminating Character-wise Data Collection这一节中,将提出的无需训练的身份一致性建模方法与视点条件图像翻译模型相结合,以实现身份一致性和角色生成的多样性。
一种更简单的方法是直接使用视点条件图像翻译模型中的多视图图像作为定制的训练数据。
但是在实验过程中发现,直接生成的结果往往会出现失真,或者不同视点的图像在颜色和纹理上存在较大差异。

出于这个原因,需要利用上面的一致性建模方法来为每个角色获得纹理和结构一致的图像。
实验部分
后续更新
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/08/论文精读-AutoStory-Generating-Diverse-Storytelling-Images-with-Minimal-Human-Effort/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!