

关于一致性角色问题的论文相关汇总及分析探究
一致性角色问题
比如,我想生成一个人物的不同的动作图像,但是衣服、发型、相貌...要保持不变。
或者想根据一个已有的角色,不训练LoRa,就能生成各种海报图....
生成一致性角色,是当前SD绘画的难题,目前普遍的方法就是,收集多个角色的素材,然后训练LoRa。
但是图像本身就是用模型生成的啊,不可能有多张同样装扮、相貌的素材,总不能先让模型自由生成,然后再人工选出来差不多一致性的数据吧,这样做的代价也太高了,总得通过其他手段从根本上解决问题。
下面就汇总几篇相关的工作,并且对各个工作展开探讨。
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
这篇写过博客了,博客链接
总的来说就是一个聚类
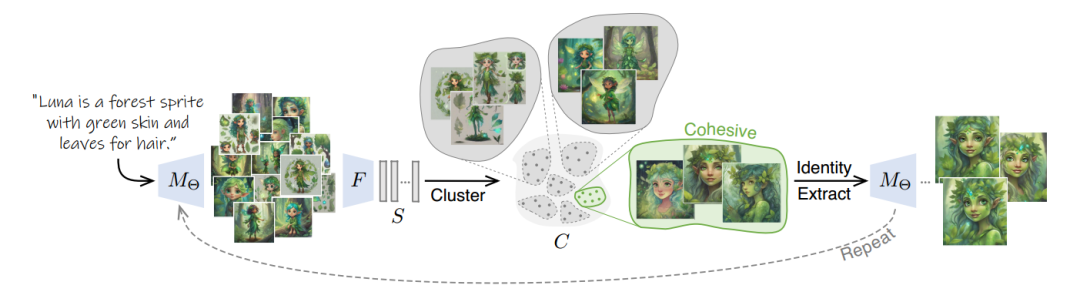
它的本质是,用SDXL根据提示词出很多图像,看了原文,应该是生成了120张,然后把这些图进行聚类,找到那堆最合适的数据,去训LoRA
但是这个不适用于本身已经设计好的图像,只能用模型去生成,局限性太大,成本比较高。
AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort
这篇写过博客了,博客链接
这个主要是为了自动生成绘本故事,可以预先输入需要参考的形象,也可以直接用文字描述去生成绘本故事。
既然是故事,就涉及到一些故事编写问题和分镜问题。
这篇论文在获取故事要求后,先生成几段故事,每段故事要对应一个图像。
然后,会根据每个分镜的故事内容,生成一些画面布局,也就是下图的Layout。至于这个是怎么生成的?是拿了一些场景去与LLM一起训过的。
每个物体位置都是使用全局prompt和局部prompt去最终确定的。全局prompt描述整个故事图像的全局上下文,而局部prompt则侧重于单个对象的细节。
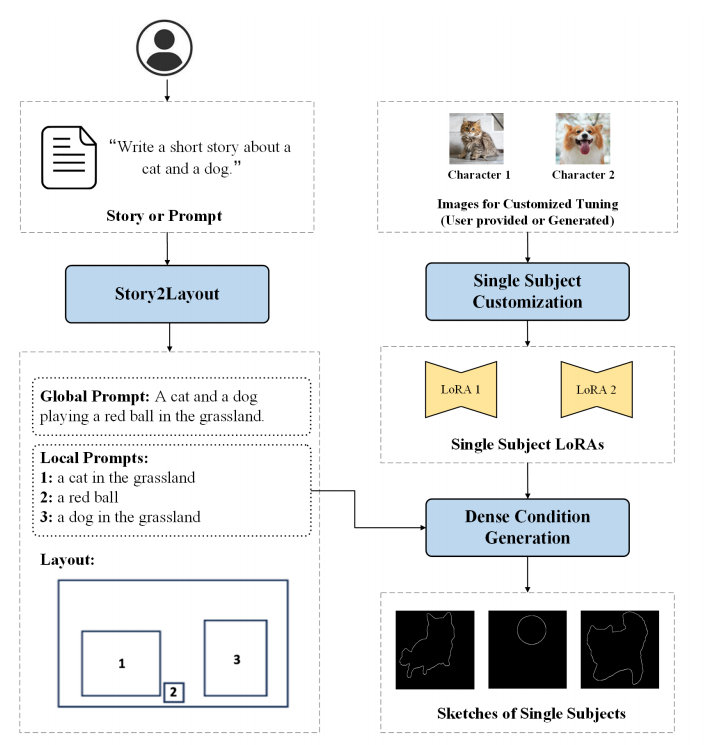
是不是觉得到layout这一步就可以生成了?
但是只用layout,生成的质量不太稳定,并且有些图像和布局不完全匹配,可以看下实验结果,第二列的就是只有layout。

由于边界框提供的信息有限,在有限的指导下,让模型一次生成大量内容比较困难,后面就引入了一个Dense Condition,也就是草图或是关键点指导。
这一步主要是,先根据局部的框,利用局部prompt逐个生成图像,就能获得一个比较高质量的单目标生成图。

接下来就是提取这个边界,用的是Grouning-DINO先检测到物体的边界,然后用SAM得到蒙版,这样就很容易获取到目标边缘了,上面的图画的也比较明白。
如果是人物的话,也可以用人体骨骼关键点来进行条件控制。
然后把控制用的条件图粘贴到原图像对应的layout中,用t2i-Adapter相关方法进行控制。
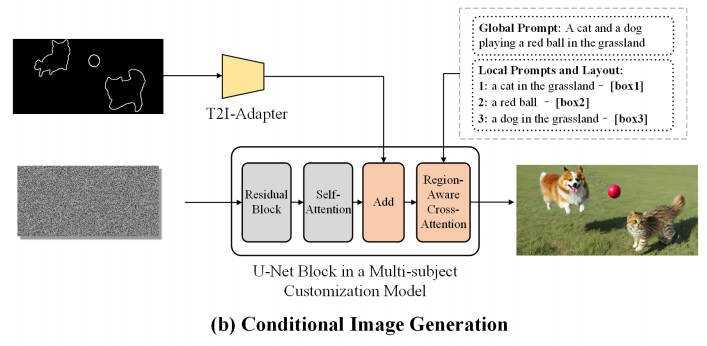
上面的操作都是全自动的,更多细节操作在论文里,可以看看。
其实使用T2I-Adapter生成多角色图这块,就是参考的腾讯的Mix-of-Show工作,这个有源码可以看看。
现在的问题就是,这个一致性的角色是怎么生成的,只看到了总流程图上有俩lora,但是原文的方法中并没提到这个,但是引言和实验结果都有提到,是参考了ICML2023 oral paper《Cones: Concept Neurons in Diffusion Models for Customized Generation》
他这个论文主要是发现了模型中的一小簇神经元对应了某个概念,因此可以更轻量化地训练lora吧,具体怎么搞的还没开,没有源码,但是论文给了训练参数,可以研究下。
Mix-of-Show
TaleCrafter
Cones Concept
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/09/一致性角色生成问题的汇总与探究/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!