

前言:上海交大联合多所高校共同发布的Alpha-CLIP,这个Alpha-CLIP是CLIP的加强版,我觉得这个Alpha-CLIP可以方法很多领域的工作中,所以对这篇工作进行简读,了解基本原理,重点看它是怎么和其它基础模型进行结合的,并将其引入到当前的工作中。
1 Motivation
Contrastive Language-Image Pre-training(CLIP),为了更好的理解和控制图像编辑,将重点放在感兴趣的特定区域变得很重要,这个Alpha-CLIP是CLIP的增强版本,带有辅助alpha通道来建议关注区域,并通过构建的millions的RGBAregion-text对数据进行微调。
Alpha-CLIP既保留了CLIP的视觉识别能力,又能精确控制图像内容的重点。
2 简要介绍
之前改进CLIP的做法:
- 第一种方法:将感兴趣的区域裁剪成不同的小块/对图像、特征和attention masks进行mask来排除不相关区域。但是这种方法破坏了(in cropping)并忽略了(in masking)上下文信息,而上下文信息对于精确的图像理解和推理很重要。
- 第二种方法:在提供给CLIP的图像上,通过circles/mask coutour来突出感兴趣的区域。这种方法虽然user-friendly,但它改变了图像的原始内容,这将导致不良的识别和生成结果。

为了在不损害原始图像的情况下实现区域聚焦,这里提出了Alpha-CLIP,它通过额外的alpha通道输入合并感兴趣的区域来改进CLIP。
引入的alpha通道与RGB通道一起,使Alpha-CLIP能够专注于指定区域,同时保持对上下文信息的感知。
虽然使用CLIP模型初始化,但alpha-CLIP的训练仍需要大量的region-text对数据,使用Segment Anything Model(SAM)和 用于图像字幕的多模态大模型(如BLIP-2),开发一个有效的pipeline来生成millions的易于转换为RGBA-text data的region-text pairs数据。
经过region-text 和 image-text 数据的混合训练后,alpha-CLIP可以在保持CLIP视觉识别精度的同时,专注于特定区域。
2.1 RGBA Region-Text Pair Generation
工作的第一部分是 RGBA Region-Text Pair Generation,但这一部分是在说用什么数据在训练这个Alpha-CLIP,同时说明了这个数据是怎么生成的,作者构建了一套新的pipeline来生成 region-text pair数据。
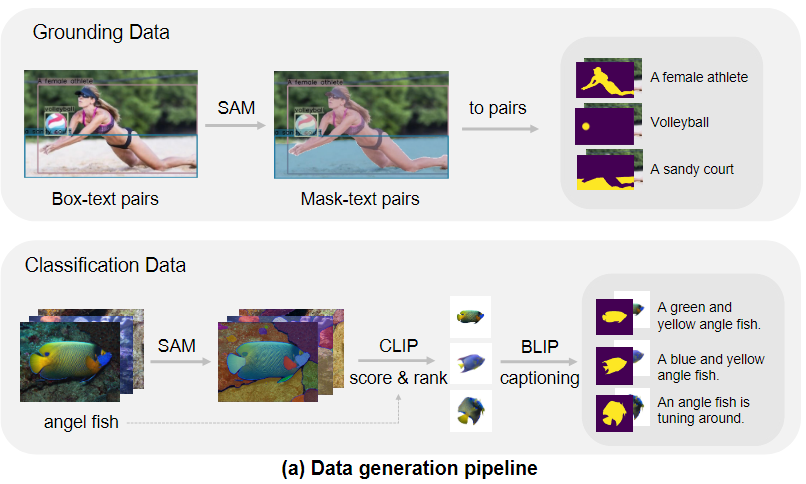
但是我们使用这个Alpha-CLIP基本是会直接调用预训练好的,所以这部分先不用太关注。
PS:当你的工作中需要对Alpha-CLIP做微调的时候,一定要看这部分。
2.2 Alpha-CLIP
Model structure
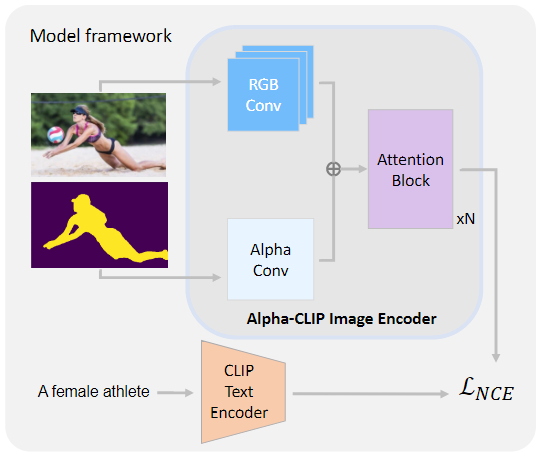
Alpha-CLIP 主要是对 CLIP 的结构进行轻微修改和微调。
在 CLIP 图像编码器的 ViT 结构中,在第一层对图像进行RGB卷积(图中蓝色部分)。
引入了一个与 RGB Conv 层平行的额外 Alpha Conv 层,它使 CLIP 图像编码器能够接受额外的Alpha通道作为输入。
Alpha 通道输入设置为[0,1]的范围,其中1表示前景,0表示背景。将Alpha Conv核权值初始化为零,确保初始Alpha-CLIP 忽略Alpha通道作为输入。
Training Method
- 在训练过程中,保持 CLIP 的 text encoder 不变,完整地训练 Alpha-CLIP 图像编码器。
- 与处理alpha通道输入的第一个卷积层相比,对随后的变压器块应用了较低的学习率。
- 为了保持 CLIP 对完整图像的全局识别能力,在训练过程中采用了特定的数据采样策略:设置采样比,表示为\(r_s = 0.1\) ,以便偶尔用原始 图像-文本对 替换生成的 RGBA -文本对,并将alpha通道设置为full 1。
Alpha-CLIP for downstream tasks
经过训练,Alpha-CLIP具有专注于指定区域和控制编辑的能力。Alpha-CLIP可以通过即插即用的方式提高CLIP在各种基线上的性能,包括识别、MLLM和2D/3D生成等各种下游任务。
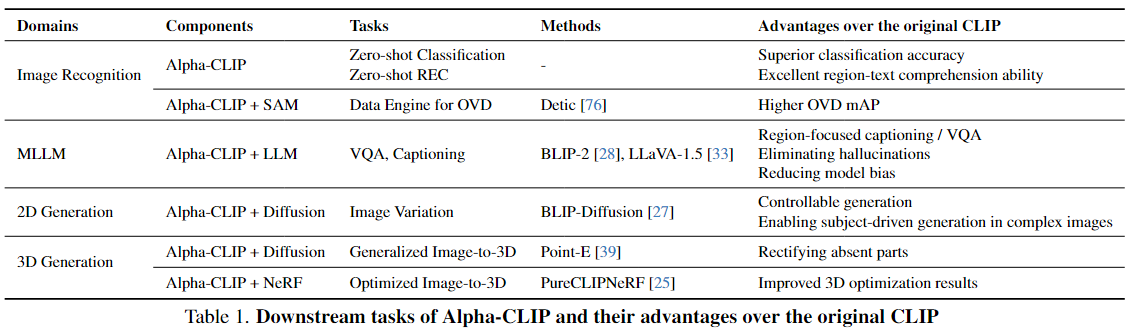
3 在下游任务中如何应用Alpha-CLIP
3.1 图像分类
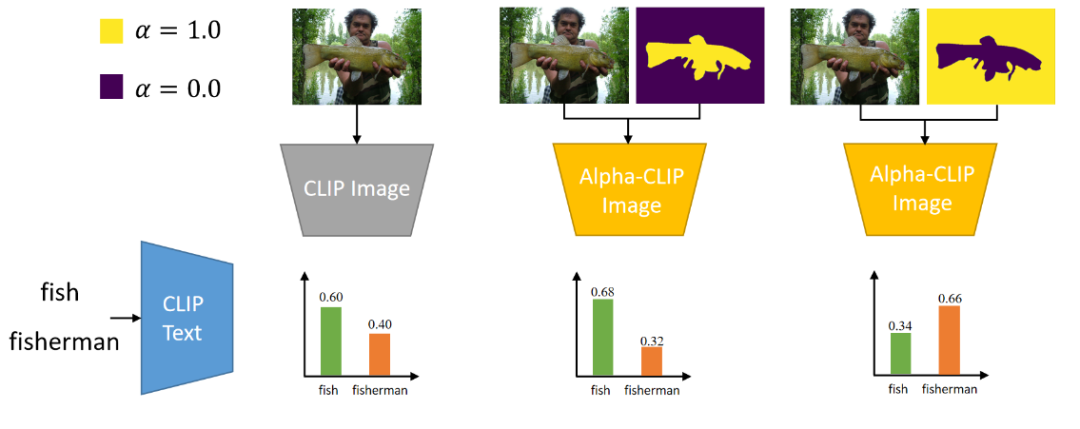
对于ImagNet的一张图片,可以通过alpha-map控制CLIP去关注鱼或渔夫。

以ImageNet的Zero-Shot Classification作为评价指标,在对全图进行识别时,Alpha-CLIP可以保持原本CLIP的分类准确率。进一步地,在给出了需要关注区域的长方形box或者mask时,Alpha-CLIP可以进一步提升分类准确率。
3.2 与LLM结合

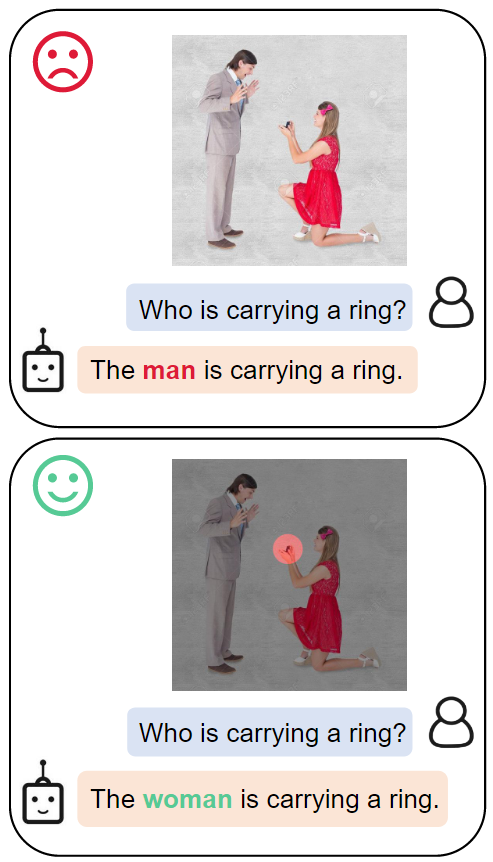

将主流的LLaVA-1.5中的CLIP基座模型替换为Alpha-CLIP,用户可以通过简单地用画笔标记处需要关注的区域,从而进行指定区域的对话交互。
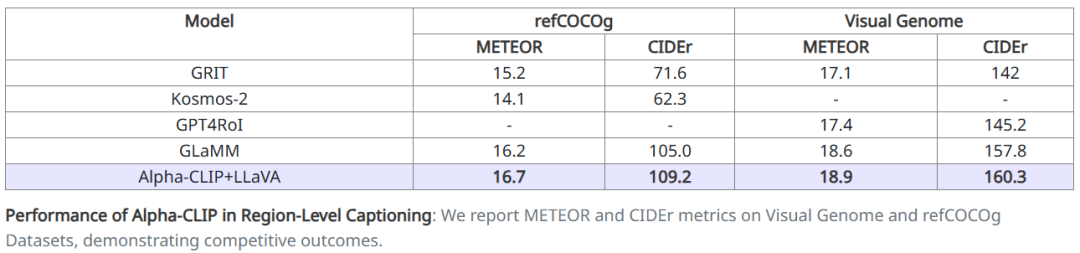
在定量实验方面,通过LLaVA测试了MLLM的region caption能力。通过在RefCOCO和VG上分别进行finetune,取得了SOTA的region caption分数。
3.3 与Diffusion Model结合


Stable-Diffusion是目前主流的2D图片生成模型,其Image Variation版本可以实现“图生图”,其中图片的编码器也是CLIP模型。通过将该模型替换为Alpha-CLIP,可以实现更复杂图片中指定物体的生成(同时较好地保留背景)。如上图所示,使用原始的CLIP会生成同时具有狮子和老虎特征的“狮虎兽”,而Alpha-CLIP能够很好地区分两个物体,从而指导Stable Diffusion模型生成更专一的图片。更多结果见下图

总结
本文介绍的这项工作提出了Alpha-CLIP模型,该模型引入了一个额外的alpha通道,用于指定感兴趣的区域。通过对数百万个RGBA区域-文本对进行训练,Alpha-CLIP不仅表现出卓越的区域关注能力,而且确保其输出空间与原始的CLIP模型保持一致。这种一致性使得Alpha-CLIP在CLIP的各种下游应用中能够轻松替代,无缝衔接。
实验证明了,当提供特定关注的区域时,Alpha-CLIP展现出了更强大的Zero-Shot识别能力,并验证了它在许多下游任务中的有用性。CLIP的应用远远超出了本文的范围。
但是现在的Alpha-CLIP有一个很大的局限性,即Alpha通道不能再中间值之外进行泛化(只能接受0,1两个值),也就是无法指令注意力幅度,这将会是基于Alpha-CLIP的一个改进方向。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/11/论文简读-Alpha-CLIP-A-CLIP-Model-Focusing-on-Wherever-You-Want/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!