

前言:这又是一篇关于角色一致性的工作(也是subject driven相关的工作),这篇工作由中山大学联合腾讯AI lab发布,在2023.6发布在arXiv上。这篇工作提供了一种很有意思的 Celeb Basis 的想法,可以迁移到其他的一致性工作中。
1 Abstract
现在存在对预训练大型文本到图像模型进行定制化的精细需求。
- 先前的方法:所新增的concept在组合能力方面往往较原始concept较弱,即使在训练过程中提供了数张图像。
- 提出的方法:只需一张人脸照片和仅1024个可学习参数,在3分钟内将独特的个体无缝集成到预训练扩散模型中。这样可以轻松生成这个人的图像,以任何姿势或位置与任何人进行互动,并根据文本提示做任何想象得出的事情。
- 具体的做法:首先分析并构建了来自预训练大型text encoder的embedding space中明确定义的celeb(名人基础)。然后,给定一个人脸照片作为目标身份,通过优化该基础的权重并锁定所有其他参数,生成其自身的嵌入。借助所提出的celeb,定制的模型中的新身份展示了比之前的个性化方法更好的概念组合能力。此外,这个模型还可以同时学习多个新身份,并在彼此之间进行互动,而先前的定制模型则无法做到。
2 Method
这项工作的重点:将human concept注入扩散模型中。
受到3DMM 的启发,该模型用明确定义的basis上的平均值和权重值的组合代表新的面部特征。
构建了一个类似的basis,用于预训练stable diffusion中名人姓名的embedding,通过basis coefficients(基础系数),能够将任何新的人物表示为训练过的扩散模型中的一部分。
2.1 方法总览
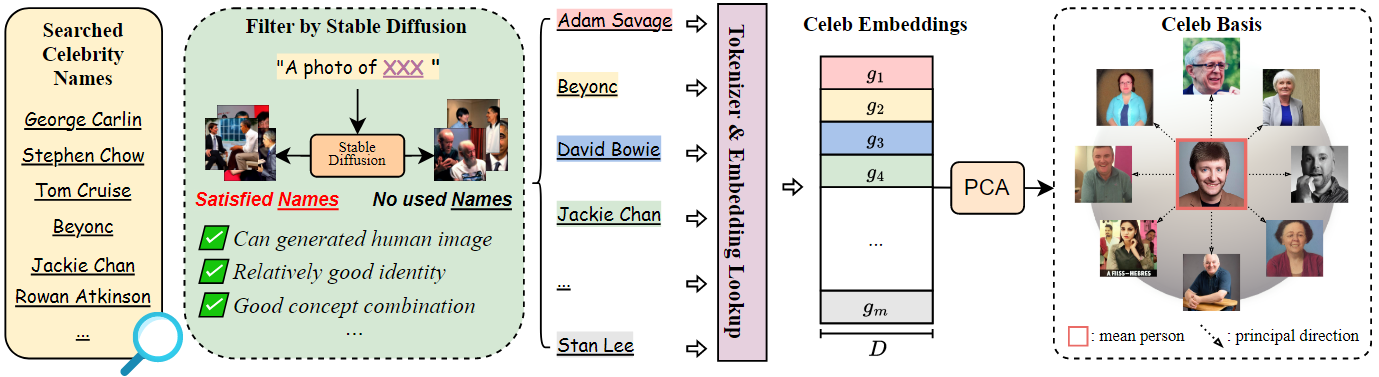
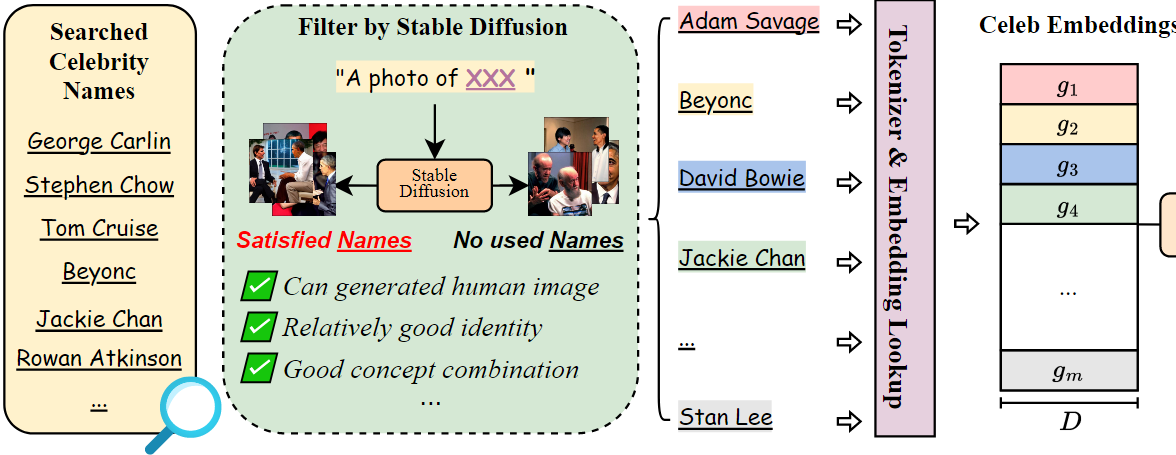
首先从互联网收集了一批名人的姓名,并用stable diffusion对其进行筛选。通过这样做,获得了691个名人姓名,并使用CLIP 的tokenizer(分词器)提取文本嵌入。
然后,通过主成分分析(PCA)构建了一个celeb basis。
为了用PCA系数表示一个新的人物,使用预训练的人脸识别网络作为给定照片的特征提取器,并学习一系列系数来重新加权celeb basis,从而使得新的面孔可以被预训练的CLIP transformer encoder识别。在此过程中,只使用一张人脸照片,并固定去噪UNet和Stable Diffusion的text encoder,以避免过拟合。
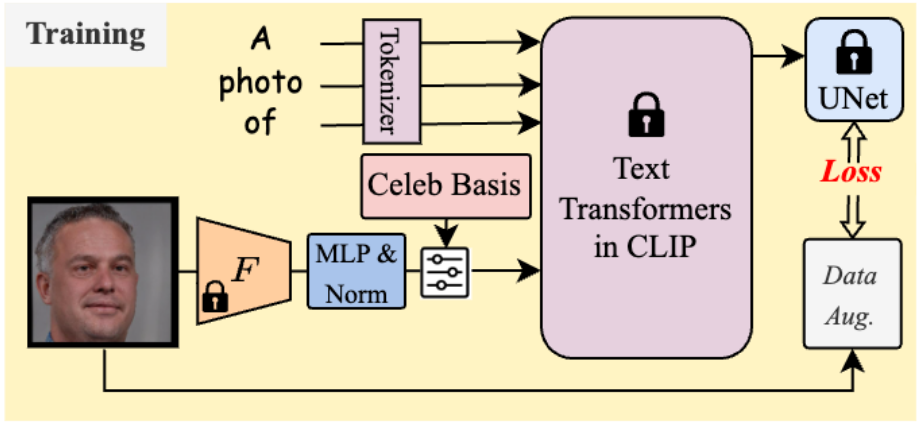
训练后,只需要存储celeb basis的1024个系数来表示新添加的身份,因为basis是模型共享的。然而简单而言,经过训练的新个体的概念组成能力得以很好地保留,因为只对训练的CLIP模型的text embedding进行重新加权,并在扩散过程中冻结权重。
值得注意的是,所提出的方法能够在任何给定的位置和姿势下生成一个注入脸部的照片。此外,它还打开了一些新的可能性,比如同时学习多个新的个体,并促进这些新生成的身份之间的无缝互动。
所以整体method分两部分:
- 首先通过名人的姓名在文本编码器的嵌入空间上分析和建立了celeb basis。
- 然后设计了一个基于面部编码器的方法,以优化celeb basis的系数,用于文本到图像扩散模型的定制化。
下面分开来说。
3 Celeb Basis
3.1 Preliminary: Text Embeddings in Text-to-Image Diffusion Models
在一个T2I模型中,给定如下组件:
- Text prompts:\(u\)
- CLIP中的Text encoder:\(e_{text}\)
(1)首先,按顺序将 \(u\) 分割并编码为 \(l\) 个 integer tokens(可能是120,23034...),通过查找dictionary,获得 \(l\) 个 word embeddings 组成的 embedding group \(g = [v_1,...,v_l]\)(每个embedding \(v_i\in \mathbb{R}^d\))。
(2)然后,text transformer \(\tau_{text}\) 在 \(e_{text}\) 中对 \(g\) 进行编码并生成文本条件 \(\tau_{text}(g)\)。
(3)条件 \(\tau_{text}(g)\) 被馈送到条件去噪扩散模型 \(\epsilon _{\theta}\left( z_t,t,\tau _{text}\left( g \right) \right)\) 中,并按照迭代去噪过程合成输出图像(其中 \(t\) 是时间戳,\(z_t\) 是图像或噪声到 \(t\) 的潜变)
之前的文本到图像模型个性化方法已经显示了文本嵌入 \(g\) 在个性化语义概念中的重要性。然而,在文本到图像模型的个性化中,它们只将其视为优化目标,而不是改善其表示。
3.2 Interpolating Abilities of Text Embeddings 文本嵌入的插值能力
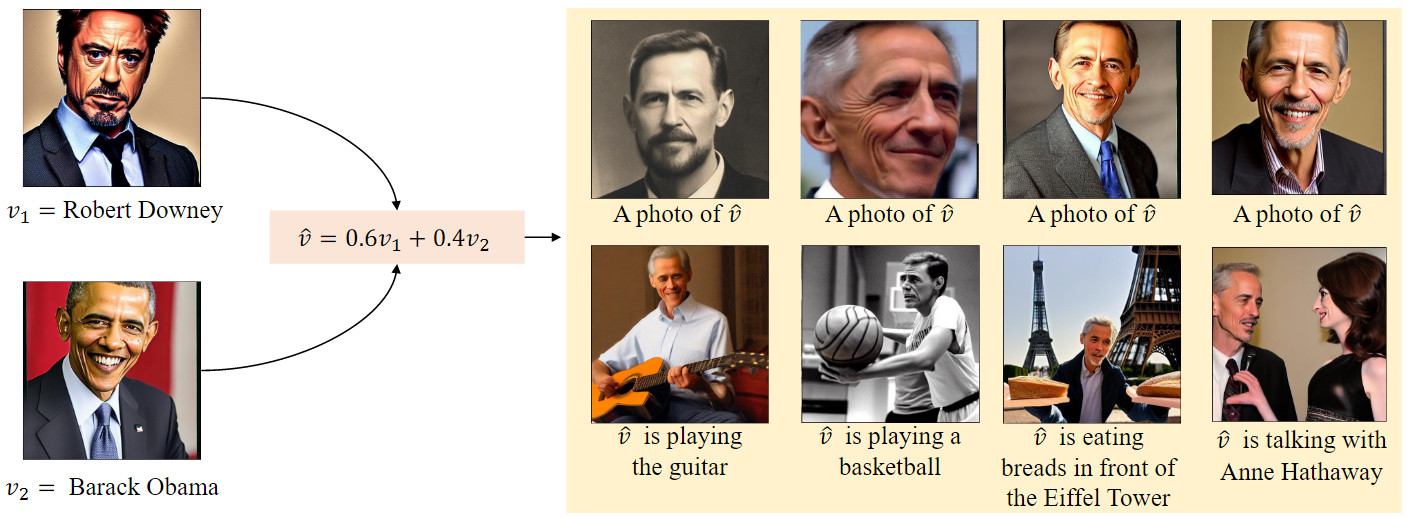
之前的研究已经表明,文本嵌入的混合有利于文本分类,这里需要验证一下文本到图像生成中的插值能力。
随机选择两个名人名字的嵌入 \(v_1\) 和 \(v_2\) ,并将它们线性组合成 \(\hat{v}=\lambda v_1+\left( 1-\lambda \right) v_2\) 。
有趣的是,插值嵌入 \(\hat{v}\) 生成的图像也包含一个人脸,并且所有生成的图像在与其他名人的表演和互动中表现良好。受上述发现的启发,可以构建了一个Celeb basis,以便每个新的身份可以处于由名人嵌入形成的空间中。
3.3 Build Celeb Basis from Embeddings of the Collected Celebrities
Step1:
首先从维基百科中爬取了大约1500名名人的姓名作为初始集合。然后,用stable diffusion构建了一个手动过滤器,通过构造每个姓名的prompt并合成图像。
满意的名人姓名应该有生成具有一致身份的人物图像的能力,并与其他名人在合成结果中互动。
最终得到了 \(m = 691\) 个满意的名人姓名,其中每个姓名 \(u_i\) 可以被分词和编码成一个名人嵌入组 \(g_i=\left[ v_{1}^{i},...,v_{k_i}^{i} \right]\)
但是每个名字的长度 \(k_i\) 可能不同,因为每个名字可能包含多个单词(或者分词器会将单词划分为子单词)。为了简化公式,我们组成了非重复的嵌入,使得每个 \(g_i\) 只包含前两个嵌入(即对于所有 \(m\) 个名人,\(k_i = 2\))。
使用 \(C_1\) 和 \(C_2\)(\(C_k=\left[ v_{k}^{1},...,v_{k}^{m} \right]\))来分别表示每个 \(g_i\) 的第一个和最后一个嵌入,可以理解它们为 first name 和 last name 的嵌入集合。
Step2:
现在需要进一步构建一个紧凑的搜索空间(受到了 3DMM 的启发,该方法使用 PCA 将高维扫描的三维面部坐标映射到一个紧凑的低维空间)
对于每个嵌入集合 \(C_k\):
- 计算其均值: \(\bar{C}_k=\frac{1}{m}\sum_{i=1}^m{v_{k}^{i}}\)
- 计算其 PCA 映射矩阵: \(B_k=PCA\left( C_k,p \right)\)
\(\bar{C}_k\in \mathbb{R}^d\)
\(PCA\left( X,p \right)\) 表示将矩阵 \(X\in \mathbb{R}^{m×d}\) 的第二维降为 \(p (p < d)\)个主成分的 PCA 操作,即将\(C_k=\left[ v_{k}^{1},...,v_{k}^{m} \right]\) 转换为 \(B_k=\left[ b_{k}^{1},...,b_{k}^{p} \right]\)
均值嵌入 \(\bar{C}_k\) 仍然代表一张脸,可以通过对 \(B_k\) 应用一些系数来得到新的脸。
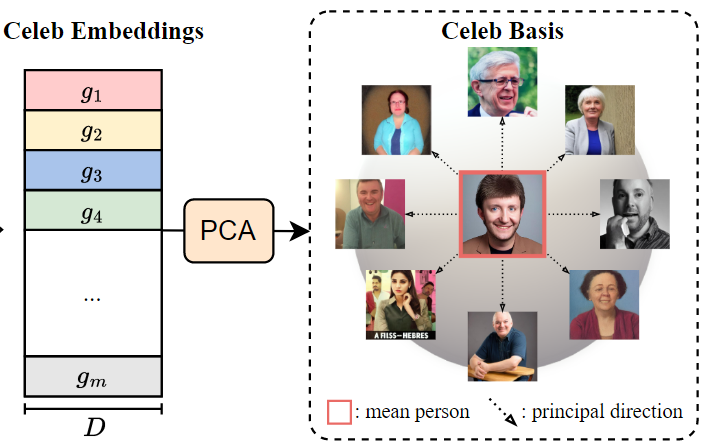
总览:
Celeb Basis是根据两个basis\(\left[ \bar{C}_1,B_1 \right]\) 和 \(\left[ \bar{C}_2,B_2 \right]\) 来定义的,就像名字的first name和last name一样。
使用相应的主成分 \(A_1\) 和 \(A_2\)(\(A_k=\left[ \alpha _{k}^{1},...,\alpha _{k}^{p} \right]\))来表示新的身份。
对于每个新的人 \(\hat{g}\) ,使用Celeb Basis的两个p维系数来表示,可以写为: \[ \hat{g}=\left[ \hat{v}_1,\hat{v}_2 \right] ,\ \ \ \ \hat{v}_k=\bar{C}_k+\sum_{x=1}^p{\alpha _{k}^{x}b_{k}^{x}} \]
在实验中,p=512 为了控制生成的身份,使用人脸编码器作为个性化方法来优化系数。(下面介绍)
4 Stable Diffusion Personalization via Celeb Basis
4.1 Fast Coefficients Optimization for Specific Identity 系数优化 (Training过程)
给定一张单独的面部照片,使用Celeb Basis将目标身份的给定面部图像 \(x\) 嵌入预训练的文本到图像扩散模型中。
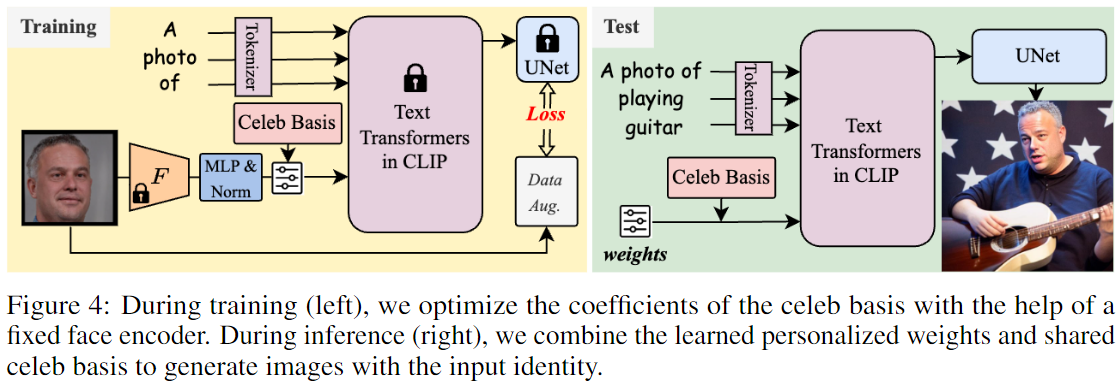
由于直接优化很难找到优化权重,所以考虑使用预训练的SOTA人脸识别模型 \(F\)(F为ArcFace),来捕捉身份鉴别模式。
具体而言,采用 \(F\) 来提取512维的面部嵌入作为先验。
然后,使用一个单层 MLP + L2 Norm 来将面部先验映射到调制系数 \(A_1\) 和 \(A_2\)。根据公式 \(\hat{g}=\left[ \hat{v}_1,\hat{v}_2 \right] ,\ \ \ \ \hat{v}_k=\bar{C}_k+\sum_{x=1}^p{\alpha _{k}^{x}b_{k}^{x}}\),可以使用预定义的Basis获得 \(x\) 的嵌入组 \(\hat{g}\)。
将 \(\hat{g}\) 的text prompts表示为 \(V^*\),将 \(V^*\) 纳入到 input face 的 text prompts ,这样就可以将其和“A photo of \(V^*\)”、“A depiction of \(V^*\)”等之间建立训练对。这里只使用简单的扩散去噪损失: \[ \mathbb{E}_{\epsilon ~N\left( 0,1 \right) ,x,t,g}\left[ \lVert \epsilon -\epsilon _{\theta}\left( z_t,t,\tau _{text}\left( g \right) \right) \rVert \right] \]
\(\epsilon\) 是未经缩放的噪声样本
\(g\) 表示包含 \(\hat{g}\) 的text embedding
在训练过程中,只需要优化 MLP 的权重,而其他模块(Celeb Basis模块、面部编码器 \(F\)、CLIP transformer \(\tau_{text}\) 和 UNet \(\epsilon _{\theta}\)) 均保持固定。
因此,训练的文本到图像网络的原始组合能力得到良好保留,避免了遗忘问题。由于只有一张照片,所以在监督数据上使用颜色抖动、随机调整大小和随机位移作为数据增强,以避免过拟合。
实验中发现即使没有正则化数据集,在先前的方法中也能够良好工作,显示了所提出方法的强大学习能力。
由于所提出的方法只涉及少量参数,在 NVIDIA A100 GPU 上每个个体只需要大约3分钟的时间,这也比以前更快。
4.2 Testing
经过训练,只需要保存Celeb Basis的两组系数 \(A_1\) 和 \(A_2\) 。
在实验中,\(p = 512\),仅需要1024个参数和半精度浮点数的2-3KB存储消耗。
然后,用户可以使用多个动作描述prompts(例如“一张\(V^*\)弹吉他的照片”)来构建prompts,以合成满意的图像。
4.3 Multiple Identities Jointly Optimization 多重身份联合
使用共享的 MLP 映射层一次学习多个身份(例如10个)。
具体来说,仅需将训练图像扩展到10个,并使用与single identity类似的过程联合训练这些图像。在没有特定设计的情况下,上面的方法可以成功生成每个身份的权重。训练后,这个方法可以在每个新身份之间进行交互,而先前的方法则无法如实验所示。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/15/论文精读-Celeb-Basis-Inserting-Anybody-in-Diffusion-Models-via-Celeb-Basis/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!