

前言:这是一篇比较老的工作,发表在CVPR2017上,由UCB的AI Lab(BAIR)提出。
1 Abstract
这篇工作调查了条件对抗网络作为图像到图像翻译问题的通用解决方案。
这些网络不仅学习从输入图像到输出图像的映射,还学习一个损失函数来训练这个映射。
这使得可以将相同的通用方法应用于传统上需要非常不同的损失公式的问题。作者证明了这种方法在从标签映射合成照片、从边缘映射重建物体和给图像上色等任务上是有效的。
一个理想的方法是指定一个High-level Goal:使输出与现实无法区分,然后自动学习一个适合实现这个目标的损失函数。
GANs就是这么做的,GANs学习一个损失函数,试图判断输出图像是真实的还是伪造的,同时训练一个生成模型来最小化这个损失。模糊的图像是不能容忍的,因为它们看起来明显是伪造的。由于GANs学习一个适应数据的损失函数,它们可以应用于许多传统上需要非常不同类型的损失函数的任务中。
2 Method
方法总览
- GANs是学习从随机噪声向量 \(z\) 到输出图像 \(y\) 的映射的生成模型,\(G : z → y\)
- 条件GANs学习从观察到的图像 \(x\) 和随机噪声向量 \(z\) 到 \(y\) 的映射,\(G : {x, z} → y\)
生成器 \(G\) 产生的输出图像与“真实”图像无法被对抗训练过的判别器 \(D\) 区分开来,判别器 \(D\) 被训练尽可能地检测生成器的“伪造”图像。
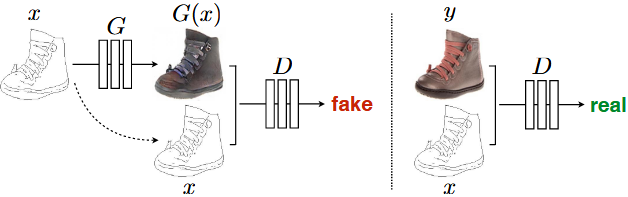
下面分点细说method。
2.1 Objective
条件生成对抗网络(Conditional GAN)的目标可以表示为: \[ \mathcal{L}_{cGAN}\left( G,D \right) =\mathbb{E}_{x,y}\left[ \log D\left( x,y \right) \right] +\mathbb{E}_{x,z}\left[ \log \left( 1-D\left( x,G\left( x,z \right) \right) \right) \right] \]
在对抗训练中:
生成器 \(G\) : 试图最小化该目标
判别器 \(D\) : 试图最大化该目标
即:\(G^*=arg\min _G\max _D\mathcal{L}_{cGAN}\left( G,D \right)\)
为了测试判别器条件的重要性,实验中还与一个不带条件的变体进行比较,其中判别器不观察x: \[ \mathcal{L}_{GAN}\left( G,D \right) =\mathbb{E}_y\left[ \log D\left( y \right) \right] +\mathbb{E}_{x,z}\left[ \log \left( 1-D\left( x,G\left( x,z \right) \right) \right) \right] \] 以前的方法发现将GAN目标与更传统的损失(如L2距离)混合在一起是有益的。 鉴别器的任务保持不变,但生成器的任务不仅是欺骗鉴别器,还要在L2意义上接近真实输出。
实验中还探索了这个选项,使用L1距离而不是L2,因为L1鼓励较少的模糊生成: \[ \mathcal{L}_{L1}\left( G \right) =\mathbb{E}_{x,y,z}\left[ \lVert y-G\left( x,z \right) \rVert _1 \right] \] 所以最终的目标是: \[ G^*=arg\min_G\max_D\mathcal{L}_{cGAN}\left( G,D \right) +\lambda \mathcal{L}_{L1}\left( G \right) \] 没有 \(z\),网络仍然可以从 \(x\) 到 \(y\) 学习映射,但会产生确定性的输出,因此无法匹配除了delta函数之外的任何分布。
过去的条件GAN已经意识到了这一点,并在生成器中除了 \(x\) 之外提供了高斯噪声 \(z\) 作为输入。
在初始实验中,发现这种策略并不有效(生成器只是学习忽略噪声)。相反,对于这篇工作的最终模型,只在训练和测试时间的多个层次应用dropout噪声形式提供噪声。尽管有dropout噪声,但是观察到网络的输出中只有轻微的随机性。
设计能产生高度随机输出的条件GAN,从而捕捉到它们模拟的条件分布的完整熵,是当时工作中所未解答的一个重要问题。
2.2 Network architectures
生成器和判别器都使用Convolution-BatchNorm-ReLu 模块
2.2.1 Generator with skips
图像到图像转换问题的一个显著特征是将高分辨率input grid映射到高分辨率output grid。此外,输入和输出在表面外观上有所不同,但两者都是相同潜在结构的渲染。因此,输入中的结构与输出中的结构大致对齐。围绕这些考虑设计生成器架构。
许多先前的工作曾经使用过一个encoder-decoder网络来解决这个领域的问题。在这样的网络中,输入通过一系列逐渐下采样的层传递,直到一个bottleneck layer,在这一点上,过程被反转。这样的网络要求所有信息流都必须通过所有层,包括bottleneck layer。对于许多图像转换问题来说,输入和输出之间存在大量的低级信息共享,并且直接在网络间传输这些信息将是可取的。(如对图像上色的情况下,输入和输出共享突出边缘的位置)
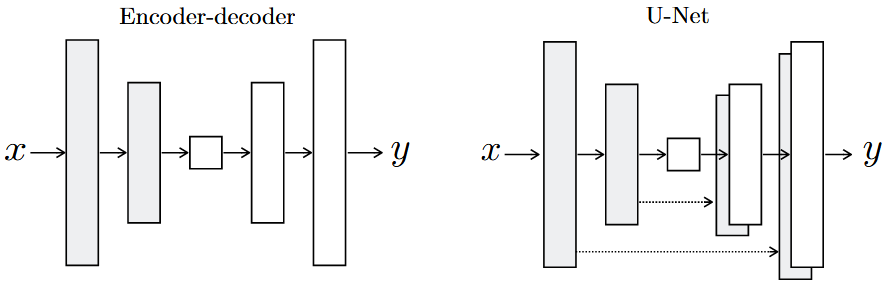
为了给生成器提供绕过像这样的信息瓶颈的方法,添加skip connections,遵循“U-Net”的一般形状。具体来说,在每个层 \(i\) 和层 \(n-i\) 之间添加skip connections,其中 \(n\) 是总层数。每个skip connections简单地将层 \(i\) 的所有通道与层 \(n-i\) 的通道连接起来。
2.2.2 Markovian discriminator (PatchGAN)
L2 loss以及L1 loss,在图像生成问题上会产生模糊的结果:

虽然这些损失无法鼓励高频的清晰度,在许多情况下它们仍然能够准确地捕捉低频信息。对于这种情况,并不需要完全新的框架来在低频率上强制执行正确性,L1已经足够。
实验结果可以看出,使用U-Net和L1的组合是ok的:

这激励我们将GAN鉴别器限制为仅建模高频结构,并依靠L1 loss来强制低频正确性(\(G^*=arg\min_G\max_D\mathcal{L}_{cGAN}\left( G,D \right) +\lambda \mathcal{L}_{L1}\left( G \right)\) )。
为了建模高频率,只需将注意力限制在局部图像块的结构上。因此,设计了一个被称为 PatchGAN 的鉴别器架构,只惩罚与patch尺度相对应的结构。该鉴别器试图对图像中每个 \(N × N\) patch进行真假分类。
通过对整个图像进行卷积来运行这个鉴别器,并对所有响应进行平均,以提供 \(D\) 的最终输出。
在实验中证明 \(N\) 可以远小于图像的完整尺寸,仍能产生高质量的结果。因为较小的PatchGAN参数较少,运行速度更快,并且可以应用于任意大的图像。
这样一个辨别器能够有效地将图像建模为一个马尔可夫随机场,假设像素在超过一个图块直径的范围内是独立的。PatchGAN可以被理解为纹理/风格丢失的一种形式。
2.3 Optimization and inference
优化网络方法:
- 在 \(D\) 上进行一步梯度下降,然后在 \(G\) 上进行一步梯度下降。(训练目标不是让 \(G\) 最小化 \(\log \left( 1-D\left( x,G\left( x,z \right) \right) \right)\),而是最大化 \(\log \left( x,G\left( x,z \right) \right)\) )。
- 此外,在优化 \(D\) 时,将目标除以2,以减慢 \(D\) 相对于 \(G\) 学习的速度。
使用小批量随机梯度下降并应用Adam求解器,学习率为0.0002,momentum parameters β1 = 0.5,β2 = 0.999
在推理时:
以与训练阶段完全相同的方式运行生成器网络。
在测试时应用了dropout,并且使用 test batch 的 statistics 来应用 batch normalization。当batch size设置为1时,此batch normalization方法被称为"instance normalization"。
在实验中,根据实验情况,使用不同的batch size,从1到10不等。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/15/论文精读Pix2Pix-Image-to-Image-Translation-with-Conditional-Adversarial-Networks/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!