

前言:这又是一篇关于故事可视化问题的工作,重点关注与增强角色图像生成质量和角色一致性,2023.12.16 由阿卜杜拉国王科技大学(KAUST)发表在arXiv上,由论文标题也可以看出,此工作聚焦于将大预言模型应用在故事可视化问题中。
Motivation就不多说了,前面几个一致性工作中说的很全,这里主要看一下Abstract中对方法的概述:
- 首先,训练了一个具有角色感知(character-aware)的LDM(Latent Diffusion Model),其以角色增强的语义嵌入(character-augmented semantic embedding)作为输入,并通过使用角色分割掩码(character segmentation masks)的交叉注意力映射监督来提高角色生成的准确性和忠实度。
- 之后,将LLM输出与第一阶段模型输入空间中存在的角色增强嵌入之间的对齐。这利用了LLM的推理能力,并具备记忆上下文的理解能力。
Method
方法简述
故事可视化的目标:
将一系列 \(N\) 个描述 \(S_1,...,S_N\) 组成的文本叙述转换成 一系列对应的 visual 帧 \(I_1,...,I_N\) ,以此来展示故事。
两阶段方法:
(1)利用 characters’ visual features 增强 文本表示,并对 character-aware LDM(Char-LDM)进行改进,以生成高质量角色。
具体改进方式:使用 character segmentation mask supervision (角色分割掩码监督),指导与相应角色相关的特定 token 的交叉注意力映射。
(2)利用 LLM 的推理能力,通过将 LLM 的输出与 Char-LDM 的输入空间对齐,以此来解决模糊指代问题(ambiguous references),进而生成一致的故事可视化。
下面分开细说。
Preliminaries
Cross-attention in text-conditioned Diffusion Models
(1)在扩散模型中,每个扩撒步骤 \(t\) 都涉及到:
基于Text embedding \(\psi \left( S \right) \in \mathbb{R}^{L×d_c}\) ,通过 U-Net 来预测 noise \(\epsilon\) from the noise code \(z_t\in \mathbb{R}^{\left( h×w \right) ×d_v}\) 。
\(\psi\) 是 text encoder, \(h\) 和 \(w\) 是 latent space 的尺寸, \(L\) 是序列长度
(2)在 U-Net 内部:
Cross-attention layer 接受 空间潜变量 \(z\) 和 Text embedding \(\psi \left( S \right)\) 作为输入,然后将它们投影到:
- \(Q=W^qz\)
- \(K=W^k\psi \left( S \right)\)
- \(V=W^v\psi \left( S \right)\)
其中,\(W^q\in \mathbb{R}^{d_v×d'}\) \(W^k,W^v\in \mathbb{R}^{d_c×d'}\)
(3)attention score 的计算公式为: \[ A=Soft\max \left( \frac{QK^T}{\sqrt{d'}} \right) \in \mathbb{R}^{\left( h×w \right) ×L} \]
\(A[i,j,k]\) 表示对第 \(k\) 个 text token 对于 \((i,j)\) latent pixel 的注意力
在这样的背景下,cross-attention map \(A\) 中的每个条目 \(A[i,j,k]\) 量化了从第 \(k\) 个文本 token 传播到 位置 \((i,j)\) 的latent pixel 的信息传播大小。
这种语义表示和潜在像素之间的相互作用特征在各类任务上得到利用(图像编辑、视频编辑、fast adaptation)
Character-aware LDM with attention control(第一阶段)
Integrate visual features with text conditions (第一阶段 1/2)
为了在故事可视化中实现准确且高质量的角色形象,通过视觉特征增强相应角色的文本描述,并引导文本条件的注意力更多地集中在相应角色的合成上。
- 给定 text description \(S\)
- 假设在 图像 \(I\) 中生成 \(K\) 个角色
- 这些角色的图像分别为 \(\left\{ I_{c}^{1},...,I_{c}^{k} \right\}\)
- 在description 中每个角色的 the list of token indices indicating 为 \(\left\{ i_{c}^{1},...,i_{c}^{K} \right\}\)
(1)首先,使用 CLIP 中的 text encoder \(\psi\) 和 image encoder \(\phi\) ,分别获得图像中出现的角色的 text embedding 和 visual feature。
(2)然后,如果 token 代表一个角色名字,那么就要 augment the text embedding(增强文本嵌入)。
☆☆☆具体的说:将 token embedding 和 对应角色的 visual feature 连接起来,然后将其输入到一个 MLP 中,以获得增强的text embedding。(这种思路很重要!!!)
每一个 augmented token embedding 在 augmented embedding \(c\) 中的表达是: \[ c^k=MLP\left( concat\left( \left( \psi \left( S\left[ i_{c}^{k} \right] \right) ,\phi \left( I_{c}^{k} \right) \right) \right) \right) \]
\(i_{c}^{k}\) 指的是角色 \(k\) 的 index of the text token
\(I_{c}^{k}\) 指的是与角色 \(k\) 对应的图像
PS:与角色无关的 \(c\) 中的 token embedding 与 CLIP 中的 token embedding 保持一致
加强后的 embedding \(c\) 随后被用作第二阶段训练的监督,\(c_1,...c_N\) 对应于 \(S_1,...,S_N\) 的增强embedding 。
Controlling attention of text tokens (第一阶段 2/2)
先前的研究表明:生成图像的visual feature受到潜在像素和文本嵌入之间在LDM扩散过程的复杂相互作用的影响。
在普通LDM 中,单个潜在像素可以无限制地与所有文本标记交互。
因此,需要一种约束来改进这种行为,并在去噪过程中加强代表角色名字的token在特定像素上的影响力。
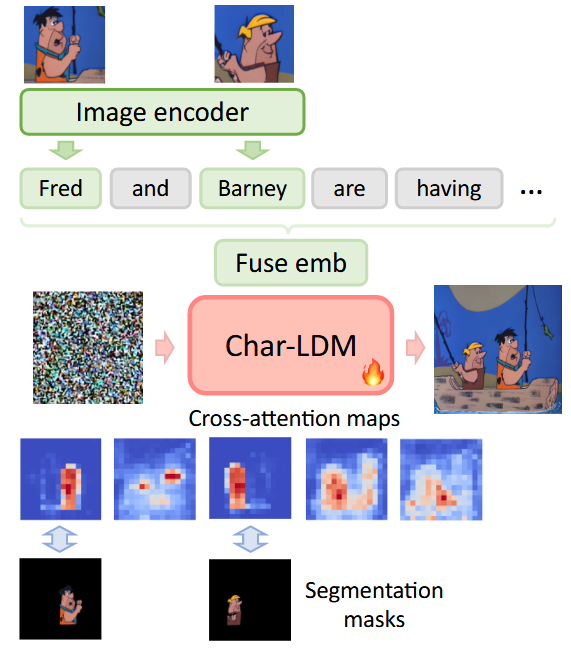
要做到这一点,需要以下两步:
- 首先,通过 SAM(Segment Anything Model)获得一个 offline segmentation mask。(用 \(M_1,...,M_K\) 表示相应的角色,以此为监督信号)
- 之后,要求每个角色 \(k\) 在 token index 位置 \(i_{c}^{k}\) 处的 cross-attention map \(A_k\) 与 二进制分割掩码 \(M_k\) 对齐,同时与无关区域 \(\bar{M}_K\) 分开。
\[ \mathcal{L}_{reg}=\frac{1}{K}\sum_{k=1}^K{\left( A_{k}^{-}-A_{k}^{+} \right)} \]
\[ A_{k}^{-}=\frac{A_k\odot \bar{M}_k}{\sum_{i,j}{\left( \bar{M}_k \right) _{ij}}},\ A_{k}^{+}=\frac{A_k\odot M_k}{\sum_{i,j}{\left( M_k \right) _{ij}}} \]
\(K\):要在图像中生成的 角色数
\(i_{c}^{k}\) :角色 \(k\) 的 index of the text token
\(\odot\) :Hadamard product
通过减少损失,它增加了 character token 对于各自 character 相关像素的注意力,同时减少他们对无关区域的关注。
此外,由于token embedding受到相应角色的视觉特征的加强(上一节说的),这种注意力控制用于加深改进的语义空间和潜在像素降噪之间的连接,从而能够提高合成角色的质量。
讨论:
上面两节说的是第一阶段的操作,分两步,第一步利用角色的visual feature 对 text token 进行加强,核心用到一个MLP;第二步利用掩码机制增强了 text tokens 中的 character token 对于各自 character 相关像素的注意力。
但是这些操作,都是针对于单个角色图像生成的考虑,对于故事可视化的任务还是不够的,体现在以下两个点:
- 故事可视化要求人物和背景的一致性,这是第一阶段增强功能所没有涵盖的方面。
- 一些特别长的描述中,出现的he、she、they等字眼,对于LDM的生成挑战还是很大的。
由此可以想到,LLM可以熟练地推断出歧义文本所指的预期特征,因此,为了解决这个问题,可以利用LLM强大的推理能力来消除此类引用的歧义,也就引入出第二阶段的内容。
Aligning LLM for reference resolution(第二阶段)
为了使LLM能够自回归地生成以先前上下文为条件的图像并解决模糊问题(歧义等),该模型必须能够:
- (i)处理图像;
- (ii)产生图像
- (iii)隐含地推导需要的角色
该模型应该满足一下要求:
- 可以学习从视觉特征到LLM输入空间的线性映射来理解图像
- 可以通过将隐藏状态与LDM所需的条件输入对齐来生成图像(该条件输入是由第一阶段Char-LDM的文本和视觉编码器编码的fused embedding 融合嵌入)
这个 fused embedding 将角色的视觉特征整合到 text embedding 中。这种角色增强embedding,连同因果语言建模(CLM),将指导LLM对参考输入进行隐式推断和生成正确的角色:

具体来说:
第一步训练
LLM的输入:由 interleaved的 互指的 text description 和 故事帧(图像、每帧图像的 length \(n\) 是 flexible的)组成,顺序是:\(\left( I_1,S_1,...I_{n-1},S_{n-1},S_n \right)\)
- 使用 CLIP 的 visual backbone 来提取 visual embeddings \(\phi \left( I_i \right) \ \in \ \mathbb{R}^{d_i}\)
- 通过可训练矩阵 \(W_{v2t}\ \in \ \mathbb{R}^{d_i×me}\) 来学习 \(Mapper_{LLM}\) (这个矩阵将 \(\phi \left( I_i \right)\) 映射到LLM输入空间中的 \(m\) 个 \(k\) 维的embedding中,\(e\) 是LLM embedding space 的维度)
- 在启用LLM生成图像的过程中,添加了额外的R token,表示为 \([IMG1],...,[IMGR]\),以表示可视化输出,并将可训练矩阵 \(W_{gen}\ \in \ \mathbb{R}^{R×e}\) 融入到冻结的LLM中
训练目标:最小化 在先前 interleaved 的 image/text tokens(\(\tau _{prev}\))条件下产生的 [IMG] tokens 的负对数似然(negative log-likelihood)
训练损失: \[ \mathcal{L}_{gen}=-\sum_{r=1}^R{\log\text{\ }p\left( \left[ IMG_r \right] \ |\ \tau _{prev},\left[ IMG_{<r} \right] \right)} \]
\[ where\ \ \tau _{prev}=\left\{ \phi \left( I_{<i} \right) ^TW_{v2t},\psi \left( S_{1:i} \right) \right\} \]
\(i\ \in \ \left[ 2,n \right]\) 表示 text description 的数量
第二步训练
为了使 LLM 产生的[IMG] tokens 与 LDM 输入空间保持一致,利用基于 transformer 的 \(Mapper_{LDM}\) 将 [IMG] tokens 投影到第一阶段的带有 \(L\) 个可学习 query embeddings \((q_1,...,q_L)\) 的 LDM 输入空间中。
(注意!!!这部分的操作和 GILL、Q-Former中的操作一模一样,值得考究)
训练目标:将 \(Mapper_{LDM}\) 的输出 \(Gen Emb\) 与 LDM 的增强条件文本表示 \(Fuse Emb\) 之间的距离最小化。
训练损失: \[ \mathcal{L}_{align}=\lVert Mapper_{LDM}\left( h_{\left[ IMG_{1:R} \right]},q_1,...,q_L \right) \ -\ c_i \rVert _{2}^{2} \]
\(h_{\left[ IMG_{1:R} \right]}\) 表示 LLM 的 [IMG] token 的最后隐藏状态
假设可以在没有参考 \(S_i'\) 的情况下访问原始文本。那么 \(c_i\) 是由第一阶段模型的文本和视觉编码器编码的标题 \(S_i'\) 的增强文本嵌入。
举个栗子:
\(S_i\) :"They are talking to each other" 那么 \(S_i'\) 就会是:
\(S_i'\) :"Fred and Wilma are talking to each other"
这个存在歧义的文本,通过增加角色视觉特征,帮助LLM在使用非正式语言建模时有效消除歧义。
推理过程
模型依次根据文本描述可视化的故事。
- 1 处理初始帧 \(S_1\) 的 text description ,专注于帧生成,限制 LLM 仅生成 \(R\) 个特定的[IMG]tokens
- 2 将这些token embeddings 输入到第一阶段 Char-LDM中,从而生成第一帧 \(I_{1}^{gen}\)
- 3 LLM 采用包括第一帧 \(S_1\) 的text description、生成的第一帧 \(I_{1}^{gen}\) 以及第二帧 \(S_2\) 的text description在内的上下文历史作为输入
这个过程重复进行,以逐步可视化整个故事。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/18/论文精读-StoryGPT-V-Large-Language-Models-as-Consistent-Story-Visualizers/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!