

先说一句,这篇论文写的非常好,通俗易懂,其中的贡献点也能引起很多思考,十分推荐。
前言:这是MIT在今年六月份发在arXiv上的,主要做的是subject-driven,涉及到了layout generation,工作突出一个便宜高效,与fine-tuning-based的方法相比,该模型实现了300倍至2500倍的加速和2.8倍至6.7倍的内存节省,并且对于新主体不需要额外的存储空间(仅使用前向传播)相当牛逼!
重点关注:
一种特殊的segmentation maps and cross-attention regularization手段对attention map的影响(有些工作也通过bounding box来实现这一效果)
1 Introduction
1.1 motivation
目前Subject-Driven text-to-image generation method主要受到两个限制:
- Cost of personalization(个性化的成本)
- Identity blending for multiple subjects(多个subjects的身份融合)
个性化成本高,因为需要对每个 new subject 去 fine-tuning 模型,内存消耗和反向传播计算量引入了计算开销和较高的硬件需求,模型调整的计算量限制了这些模型在不同平台上的适用性。
多subjects融合的问题现有技术也很难处理的很好:

由此可以看出,我们现在需要一个tuning-free或者尽可能少tuning的模型,同时能够很好的进行subjects融合(不再仅仅依赖名人姓名)
1.2 方法概述
FastComposer,一种 tuning-free 的个性化multiple subjects文本到图像生成方法。
通过捕捉个体在文本条件下的独特identity的embedding来替代generic word tokens(例如"person")。
- 使用一个 visual encoder 从参考图像中 derive 这个 identity embedding
- 然后使用这个 identity embedding 的feature来 augment the generic text tokens
这样可以基于 subject 增强条件来进行图像生成。这个模型只需要前向传播就可以生成具有指定subject的图像,并且可以进一步与模型压缩技术相结合,以提高部署效率。(突出一个高效和轻量化,同时解决了上面的两个问题)
关注 multi-subjects identity 混合的问题,使用一个 unregulated cross-attention ,当文本中包含两个 "person" token的时候,每个token的attention map都会同时注意到图像中的两个人物,而不是每个token与图像中的一个独立人物相关联。
为了达到这样的效果,在训练期间使用standard segmentation tools来监督subject的attention map 和 segmentation mask(即交叉注意力定位 cross-attention localization)。这种监督明确地指导模型将subject's feature映射到图像的不同且不重叠的区域,从而促进高质量多主体图像的生成。(segmentation and cross-attention localization只在训练阶段使用)
2 Preliminaries
这部分是一些基础的内容,我就简要写一点。
Stable Diffusion
Backbone Network:Stable Diffusion(SD)由三部分组成:变分自动编码器(VAE)+ U-Net + text-encoder
- VAE encoder \(\mathcal{E}\) 将 image \(x\) --> latent representation \(z\) ,\(z\) 在前向扩散过程中通过Gaussian noise \(\varepsilon\) 扰动。
- U-Net (parameterized by \(θ\))通过预测噪声来去噪纯噪声的latent representation,该去噪过程可以通过cross-attention以text prompts为条件。
- text-encoder \(\psi\) 将 text prompts \(\mathcal{P}\) --> conditional embeddings \(\psi \left( \mathcal{P} \right)\)
在训练过程中,最小化以下loss函数来优化网络: \[ \mathcal{L}_{noise}=\mathbb{E}_{z~\mathcal{E}\left( x \right) ,\mathcal{P},\varepsilon ~\mathcal{N}\left( 0,1 \right) ,t}\left[ \lVert \varepsilon -\varepsilon _{\theta}\left( z_t,t,\psi \left( \mathcal{P} \right) \right) \rVert _{2}^{2} \right] \]
\(z_t\) 是在 time step \(t\) 时的 latent code
在推理时:从 \(\mathcal{N}\left( 0,1 \right)\) 中采样一个随机噪声 \(z_T\),并通过 U-Net 迭代地对其进行去噪,得到初始潜在latent representation \(z_0\)。最后,VAE decoder \(\mathcal{D}\) 将 latent code 映射回像素空间,生成最终图像 \(\hat{x}=\mathcal{D}\left( z_0 \right)\)。
3 Method
3.1 Tuning-Free Subject-Driven Image Generation with an Image Encoder
无需调参的 subject-driven 图像生成与图像编码器
3.1.1 Augmenting Text Representation with Subject Embedding
为了实现 Tuning-Free 的 subject-driven 图像生成,可以利用从 reference subject image中提取的视觉特征来增强文本提示。
- 给定一个 text prompts: \(P=\left\{ w_1,w_2,...,w_n \right\}\)
- 一个参考主题图像 list:\(S=\left\{ s_1,s_2,...,s_m \right\}\)
- 以及一个索引 list,指示哪个主题对应于文本提示中的哪个词:\(I=\left\{ i_1,i_2,...,i_m \right\} ,i_j\in 1,2,...,n\)
(1)首先使用预训练的CLIP文本编码器 \(\psi\) 和图像编码器 \(\phi\) 将 \(\mathcal{P}\) 和 \(\mathcal{S}\) --> 编码为 embedding vector。
(2)接下来,使用 MLP 来利用从 reference subject 中提取的视觉特征来增强 text embedding。(将 word embeddings 与 visual features 连接起来,并将结果增强的嵌入送入 MLP 中)
这个过程产生了最终的 conditioning embeddings \(c'\in \mathbb{R}^{n×d}\),定义如下:
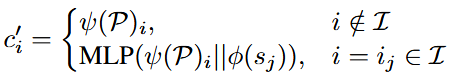
3.1.2 Subject-Driven Image Generation Training
为了实现 inference-only 的 subject-driven 图像生成,使用denoising loss 来训练 image encoder、MLP module 和 U-Net。
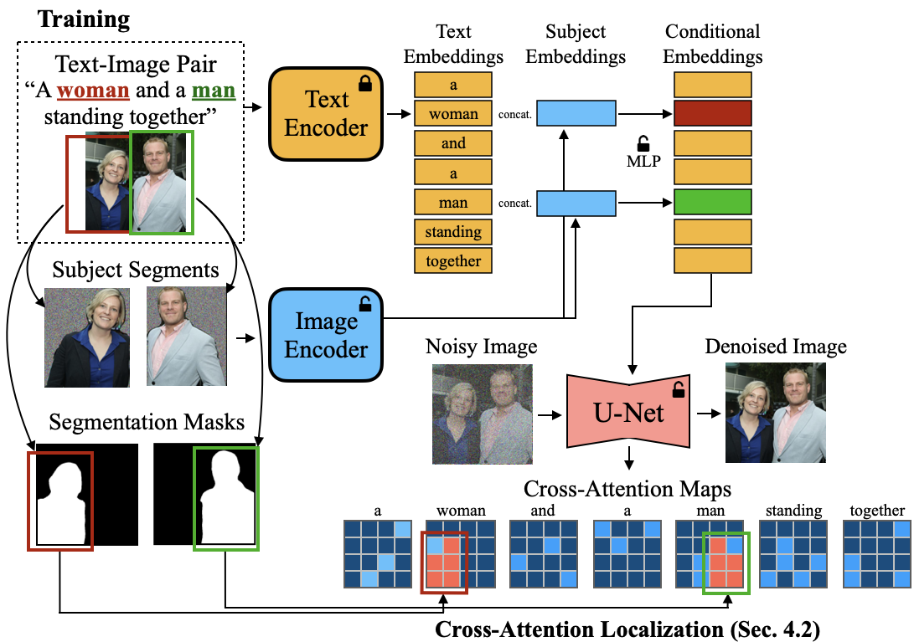
创建一个 subjec-augmented image-text 数据对来训练模型,其中image caption中的名词短语和 target image中的 subject segments 区域进行配对。
处理过程如下:
使用一个 dependency parsing model to chunk all noun phrases in image caption (例如:a woman)
使用一个 全景分割模型 to segment all subjects in image
使用 基于文本和图像相似性的贪婪匹配算法 将这些 subject segments 和 noun phrases 进行配对
在训练过程中,使用上面的主题增强的条件来去噪扰动目标图像,在编码前用随机噪声 mask 住 subject的背景,防止subject background过拟合。
3.2 Localizing Cross-Attention Maps with Subject Segmentation Masks
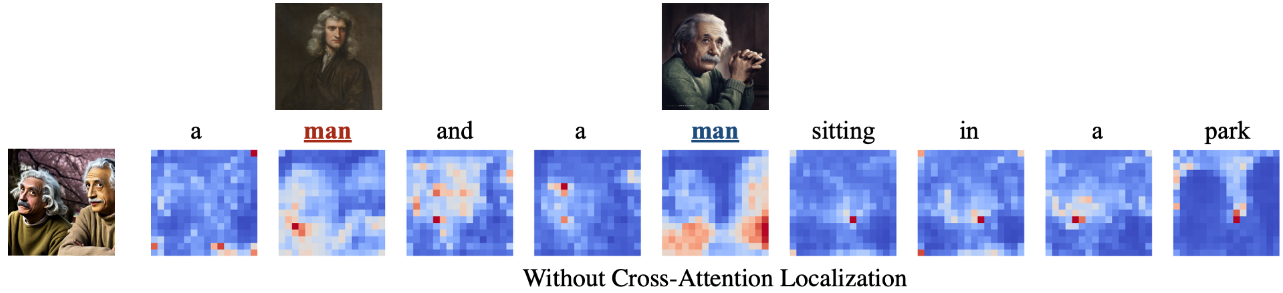
传统的 cross-attention maps 往往同时关注 所有的 subjects,这会导致在 multi-subjects image generation中出现身份混合:
通过在训练过程中在 cross-attention maps上使用 subject segmentation mask,可以解决这个问题。
3.2.1 Understanding the Identity Blending in Diffusion Models
我们来看看diffusion model中的身份融合是怎么个事。
Diffusion model中的 cross-attention机制主导了生成的图像的layout,the score in cross-attention maps 代表 信息从text token到latent pixel的传递量。
假设,身份融合问题来自于无限制的cross-attention机制(这部分需要消融),因为单个latent pixel可以关注所有text tokens,如果一个subject的区域关注多个reference subjects,就会造成身份融合。
通过下面这张图可以验证这个假设:
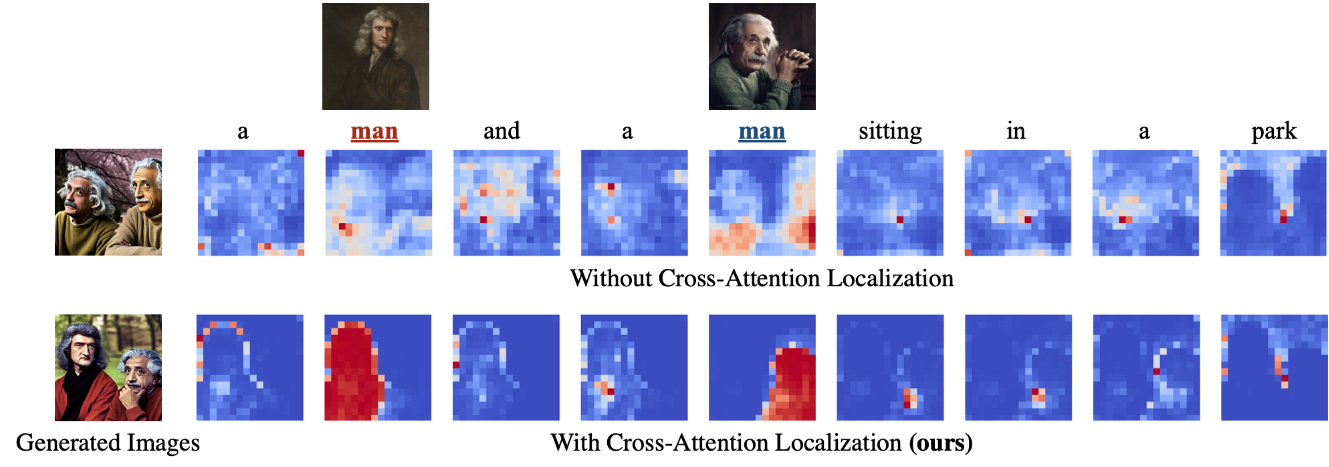
合适的cross-attention map应该类似于对目标图像的实例分割,清楚的分开不同subject相关的feature。
为了实现这一点,在训练过程中为主体cross-attention map加入正则化项,鼓励关注特定的subject区域,segmentation maps and cross-attention regularization只在训练中使用,测试时不用。
3.2.2 Localizing Cross-Attention with Segmentation Masks
一个cross-attention map \(A\in \left[ 0,1 \right] ^{\left( h×w \right) ×n}\) connects latent pixels to conditional embeddings at each layer
\(A[i,j,k]\)表示从第\(k\)个conditional token到latent pixel的信息流
理想情况:subject token的attention map应该集中到subject region,而不是在整个图像上扩散。
为了达到这个理想情况,使用reference subject's segmentation mask 来定位 cross-attention map:
- \(\mathcal{M}=\left\{ M_1,M_2,...,M_m \right\}\) 表示 reference subject's segmentation masks
- \(\mathcal{I}=\left\{ I_1,I_2,...,I_m \right\}\) 表示text prompts中每个word对应那个subject的索引
- \(A_i=A\left[ :,:,i \right] \in \left[ 0,1 \right] ^{\left( h×w \right)}\)表示第\(i\)个subject token的cross-attention map
使 the cross-attention map \(A_{i_j}\) 靠近 第 \(j\) 个 subject token 的segmentation mask \(m_j\),即 \(A_{i_j}\approx m_j\)
使用 balanced L1 loss 来最小化 cross-attention map 与 segmentation mask 的距离: \[ \mathcal{L}_{loc}=\frac{1}{m}\sum_{j=1}^m{\left( mean\left( A_{i_j}\left[ \bar{m}_j \right] \right) -mean\left( A_{i_j}\left[ m_j \right] \right) \right)} \] 那么最终整个模型的训练目标就是:(λ=0.001) \[ \mathcal{L}=\mathcal{L}_{noise}+\lambda \mathcal{L}_{loc} \]
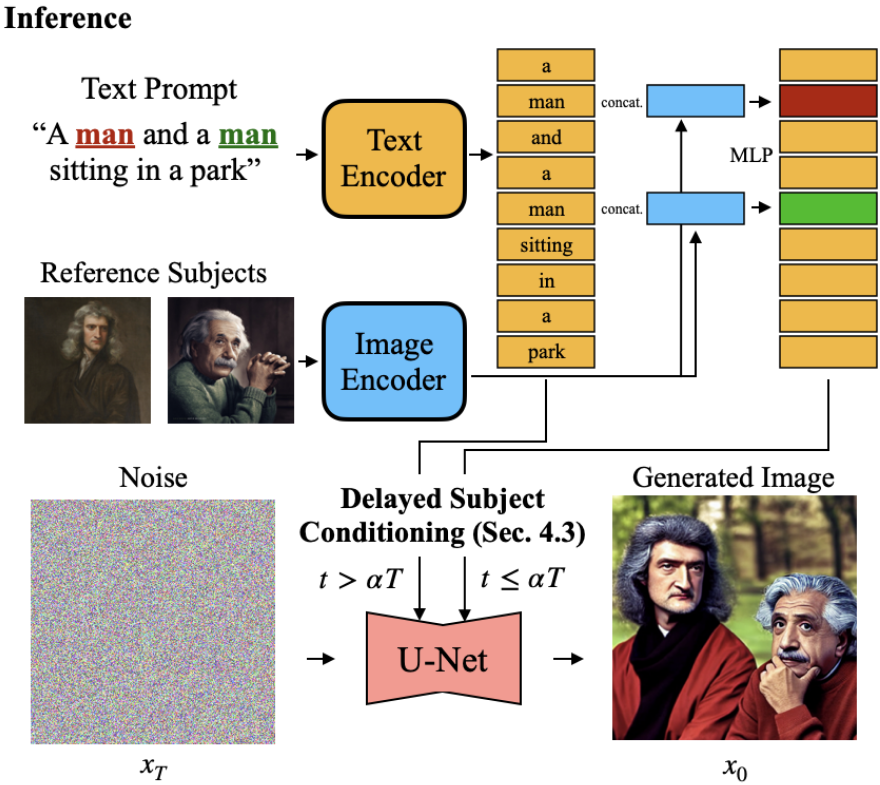
推理过程
很直观,放个图就行:
最后来欣赏一下实验结果吧,虽然真实性上有些欠缺,但是这个思路给subject-driven提供了许多可能:


PS:这个模型可能生成真实图像的效果差一点,所以作者用了很多风格生成。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/23/论文精读:FastComposer-Tuning-Free-Multi-Subject-Image-Generation-with-Localized-Attention/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!