

前言:今年6月科大和上交做的一篇工作,也是关注 Multi-subjects driven
重点关注:Learning a residual on top of the base embedding
1 Introduction
1.1 Motivation
现有的主流方法:通过 joint training 来实现 multi-subject 的定制化,即tunes the model with all subjects
存在的问题:
- 需要为每个subject组合来学习单独的模型,当subject数量增加可能会导致指数级增加的学习。
- 不同subject之间可能会相互甘涛(例如:一只有猫特征的狗)

1.2 方法简述
想通过一种简单且有效的表示来代表一个subject,并且能够进行任意subject的组合(不需要重新训练)
由此抛出两个问题:
- 如何有效地表示一个subject
- 如何有效地组合不同的subject
给定一个subject和其配套的图片,将这个特定subject的feature绑定到一个可以灵活使用的插件上,使用特定subject的图片对T2I模型的text encoder进行fine-tuning,使其可以对subject进行定制。
同时,还需要一个text-embedding-preservation loss,这个loss限制fine-tuning后的text encoder的输出(仅在特定subject的token embedding与原始的有所不同,替换),之后计算fine-tuning前后text encoder的差异,得到可以稳定的将原始类别转换为定制subject的residual token embedding。(eg:dog → customized dog)
2 Method
给定一个subject和其配套的从不同视角拍摄的图片(每个subject3-5张,有一说一,这个数据集挺奢侈的),目的是生成包含这些subject的任意组合的新图像,通过将subject-specific residual token embedding与diffusion model进行结合,并在生成过程中用layout进行引导,来实现这个过程。
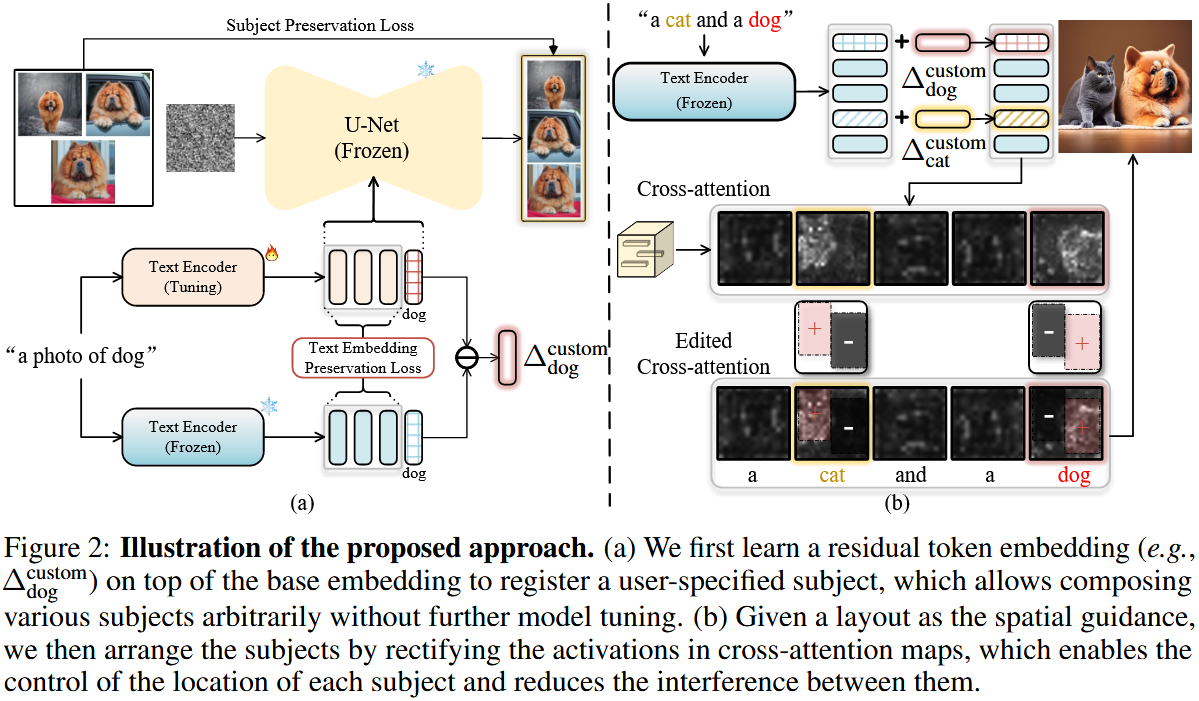
具体来说,将每个subject看做从基础subject偏移的residual token embedding(这块和celeb basis那篇工作的想法很像),也就是说将residual token embedding添加到基础subject 的embedding中就可得到对应的subject,所以如何获得这个residual token embedding很关键。
2.1 Text-conditioned diffusion model
扩散模型的内容就不重复了,原文中有这块内容,可能是凑字数的,总的来说扩散模型就是通过逐渐去噪从高斯分布中采样的变量来学习数据分布。
2.2 Representing subjects with residual token embedding(关键点☆☆☆)
2.2.1 Representing subjects with residual text embedding
目标是用text encoder的output domain中的一个 residual text embedding 来表示每个subject。
一个理想的residual text embedding \(\varDelta ^{custom}\) 可以将基础 subject转移到特定subject上,举个例子:一个具有embedding input (E(“a photo of dog”)+ \(\varDelta ^{custom}\)) 的模型 \(\epsilon _{\theta}\) 可以生成特定“dog”的照片。
实现这个目标的方式是从 source (original) text encoder 到 target (fine-tuned) text encoder 计算一个 embedding direction vector,微调后的text encoder \(E^{costom}\) 需要能够自定义 subject \(s\) 并与 原始 diffusion model \(\epsilon _{\theta}\) 结合。(类似DreamBooth,\(E^{costom}\) can be trained with the subject-preservation loss as:) \[ L_{sub}\left( E^{custom} \right) =\mathbb{E}_{\left( x,c \right) ~D_s,\epsilon ~\mathcal{N}\left( 0,1 \right) ,t}\left[ \lVert \epsilon _{\theta}\left( x_t,E^{custom}\left( c \right) ,t \right) -\epsilon \rVert _{2}^{2} \right] \]
\(D_s\)={( \(x_{j}^{s}\) , "a photo of \(s\)" ) | \(x_{j}^{s}\in X^s\)} 是 subject \(s\) 的reference few-shot data
2.2.2 Regularization with a text-embedding-preservation loss
根据上面获得的 residual text embedding,只能进行single-subject的定制生成,由于这些residual text embedding应用于整个text,其中任意两个embedding可能存在显著冲突,因此不能直接合并他俩后进行推理。
所以,提出一个 text-embedding-preservation loss 来使 residual text embedding 主要集中在于 subject token 有关的text embedding上,其核心思想是尽量减少 \(E^{costom}\) 与除 subject token \(s\) 之外的其他token对应的 \(E\) 之间的差异。
还是用dog举例子,用chatgpt生成1000个包含单词 “dog” 的句子 \(C_{dog}=\left\{ c^i \right\} _{i=1}^{1000}\),然后最小化除 "dog" 之外的所有的token 对应的 \(E\) 与 \(E^{costom}\) 的差异。
比如:“a dog on the beach”
将它对应的text embedding 拆分成一个 sequence \(E\left( c \right) =\left( E\left( c \right) _a,E\left( c \right) _{dog},...,E\left( c \right) _{beach} \right)\)
希望any 不等于 "dog" 的 p 都满足 \(\lVert E\left( c \right) _p-E_{p}^{custom\left( c \right)} \rVert _{2}^{2}\)
也就是说,当\(p\) 遍历 \(c\) 中除 \(s\) 之外的所有token时, text-embedding-preservation loss 是一种正则化
整体的训练目标为: \[ L=L_{sub}+\lambda L_{reg} \] 在获取微调好的text encoder后,通过计算 \(E^{custom}\left( c \right) _{dog}\) 相对于 \(E\left( c \right) _{dog}\) 在这1000个句子上的平均位移,我们得到了 “dog” 的 residual token embedding: \[ \varDelta _{dog}^{custom}=\frac{1}{\left| C_{dog} \right|}\cdot \sum_{c\in C_{dog}}{\left( E^{custom}\left( c \right) _{dog}-E\left( c \right) _{dog} \right)} \]
2.2.3 Inference with residual token embedding
上面得到的 residual token embedding 可以直接在涉及到它的任何 subject 组合中使用
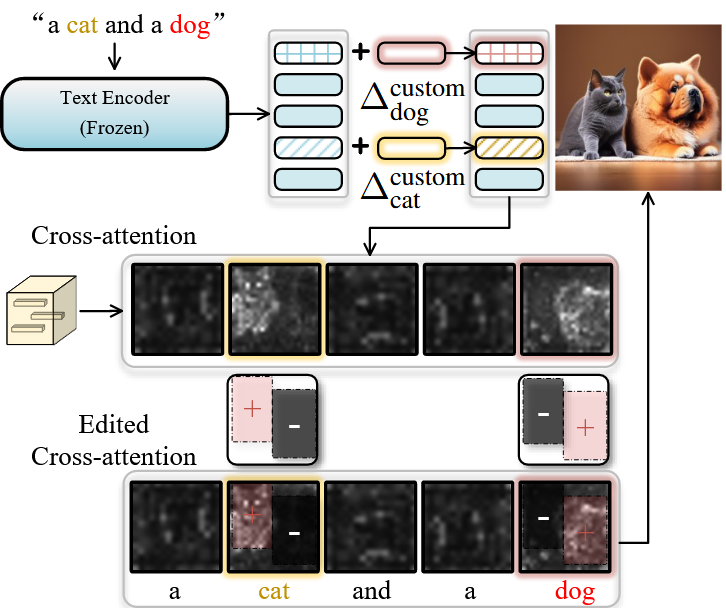
当我们使用 \(N\) 个特定subjects \(s_1,s_2,...,s_N\) 进行定制生成时,我们需要做的只是获取 \(\varDelta _{s_1}^{custom},\varDelta _{s_2}^{\text{c}uston},...,\varDelta _{s_N}^{custom}\) 并将其添加到 token embedding 中: \[ E^{final}\left( c \right) _{s_i}=E\left( c \right) _{s_i}+\varDelta _{s_i}^{custom},\ \ i=1,...,N \] 上面这个方程完全在 token 维度上进行预算,这就很便利且高效,同时 任何 residual token embedding \(\varDelta _{i}^{custom}\) 都可以重复使用,也可以和另一个 \(\varDelta _{j}^{custom}\) 相结合。
很牛逼的一点是,对于每个 subject,只需要储存一个 float32 的 vector,并不需要大量参数。
2.3 Composing subjects with layout guidance
T2I diffusion model 通常通过 cross-attention 机制将text embedding \(E(c)\) 注入到 diffusion model \(\epsilon _{\theta}\) 中。
cross-attention layer 中的 attention map 是 \(CA=\left( W_Q\cdot \varphi \left( x_t \right) \right) \cdot \left( W_K\cdot E\left( c \right) \right)\) (\(\varphi \left( x_t \right)\) 是转换后的 image feature,\(WQ\) 和 \(WD\) 表示计算 query 和 key 的参数),cross-attention map 直接影响最终生成图像的 layout。
那么下面就来关注如何通过改善 cross-attention map 来提高生成质量。
2.3.1 Strengthening the signal of target subject
multi-subject 定制的一个问题是一些subject可能无法显示出来:

一些研究认为这是由于这些subject在 cross-attention map 中的激活不足造成的,那么就可以在希望这个 subject 的区域进行信号加强。
2.3.2 Weakening the signal of irrelevant subject
multi-subject 定制的另一个问题是 subject 的属性在 subject 之间变得混淆:

一些研究认为这是由于不同 subject 在 cross-attention map 中的活动区域重叠所导致的,那么就可以减弱每个 subject 在其他 subject 区域中出现的信号。
2.3.3 Layout-guided iterative generation process
结合上面增强和减弱信号的两种想法,在实验中,将 layout \(M\) 定义为 a set of subject bounding boxes,并为每个 subject \(s\) 获取 guidance layout \(M_s\) 。

详细来说,将 \(M_s\) 分成不同的区域,在希望 subject \(s\) 出现的区域(表示为 \(R_{s}^{show}\) )中将 \(M_s\) 的值设为 正值 \(\gamma ^+\),与subject \(s\) 无关的区域(表示为 \(R_{s}^{irrelevant}\))中将 \(M_s\) 的值设为 正值 \(\gamma ^-\)。
在推理过程中,将 cross-attention 的所有输出替换为每一步的编辑结果: \[ EditedCA\left( CA,M,c \right) =Soft\max \left( CA\oplus \left\{ \eta \left( t \right) \cdot M_{s_i}|i=1,...,N \right\} \right) \cdot \left( W_V\cdot E\left( c \right) \right) \]
\(\oplus\) 表示将 \(CA\) 和 \(M\) 的相应维度进行加法运算,\(\eta \left( t \right)\) 是一个凹函数,用来控制不同时间 \(t\) 的编辑强度。
整体的算法流程

实验的设置
Dataset
这个作者真讨厌,说了跟没说一样,反正就是一些场景、宠物和物品,然后作者是从好几个地方收集来的,唉,本来这种数据集就难找,作者还不想说,奶奶个熊。
Baselines
这个模型与以下模型进行了比较:(这些工作也可以看看)
- DreamBooth(它在扩散模型中微调了所有参数,太狠了,算力多就是好)
- Custom diffusion(它在text encoder中优化了新增的word embedding 以及扩散模型中的一些参数,即从文本到潜在特征的key和value射在cross-attention中)
- Cones(也是这个作者做的工作)
实验开销
只说了用了一张A100,没说跑了多长时间,但是应该不会很久。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2023/12/27/论文精读-Cones-2-Customizable-Image-Synthesis-with-Multiple-Subjects/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!