

前言:今天来看一下Stability AI公司的最新力作:Stable Video Diffusion,这个公司上一个力作 Stable Diffusion已经得到了广泛的认可并且在工业界大范围使用,这篇工作又将图像生成拓展到了视频生成领域,还是延续工业界的土豪气息,这篇工作并没有什么花样百出的模型升级,和DALLE3一样,重点在对数据的处理,信奉大力出奇迹,事实证明效果很好,在很多下游任务上都取得了SOTA。
重点关注:视频数据治理 Camera Motion LoRA
在开始前先看一下效果,这个gif可以在Stability AI的github主页上找到:

看起来效果还不错,没有很频繁的闪动和失真。
1 Abstract
Abstract总结一下有四个比较关键的点:
- 一个问题:数据小,缺治理
- 三步走:文生图预训练、视频预训练、高质量视频微调
- 一个关键:数据治理
- 多产出:文生视频、图生视频、camera motion-specific LoRA、多视图生成
一个问题:数据小,缺治理
现在在视频生成领域的一个问题,普遍用的数据集都是高质量,但是量级很小的数据集。
而且所使用的数据集缺少一个统一的有效的策略去做治理。
三步走:文生图预训练、视频预训练、高质量视频微调(第二步最关键)
文生图预训练之前已经做过了,其实就是 Stable Diffusion,所以第一阶段实际上已经做过了。
得到文生图的模型后,要做视频生成,那就在视频的数据上做一些预训练,预训练结束后就得到一个在视频中有很好表现的base model。
base model有基础能力后,就要应用到各种各样的下游具体任务中,那就走第三步,高质量的视频微调。具体看你要做什么任务,如果要做一个文生视频的模型,那就用 文本-视频 对数据集去继续 fine-tuning 之前的base model;如果想做图生视频的模型,那就可以吧图像作为控制条件,喂到base model去 fine-tuning......
一个关键:数据治理
多产出:文生视频、图生视频、camera motion-specific LoRA、多视图生成
introduction 和 background部分就先跳过了,就是abstract的展开,其中 latent video diffusion model 的背景知识可以看一下,我这块的工作看的不多,后面会补一下。
下面直接进入method。
2 Curating Data for HQ Video Synthesis ☆☆☆
这部分我们主要关注作者是怎么做数据处理筛选治理的,然后怎么分三步走去训练你的模型的,然后是怎么应用到各个下游任务中的。
2.1 Data Processing and Annotation
其中作者提出的数据集叫做 LVD,LVD中包含近600M的视频片段,这些是怎么来的呢?我先画个图表示一下:
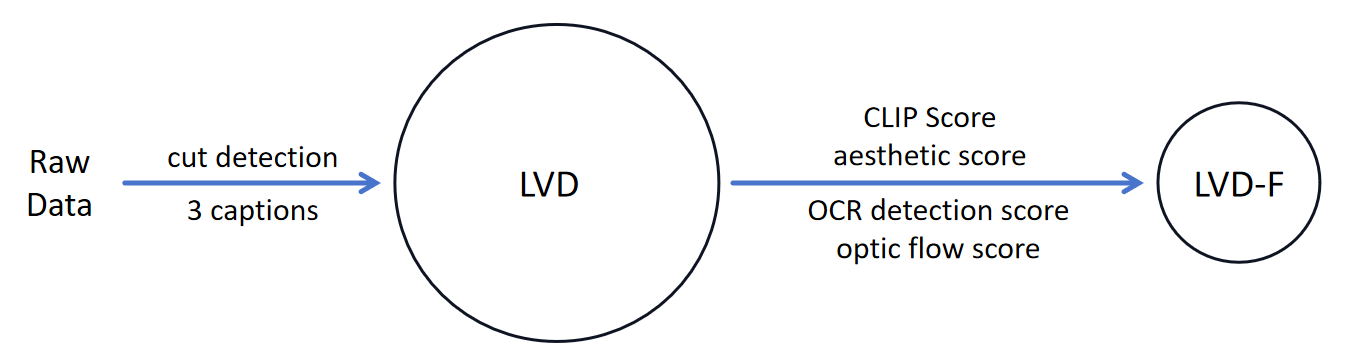
最开始当然是回去各处搜集一些 Raw Data,然后首先要做一个 cut detection。
cut detection
这个cut detection是什么?在收集到原始的视频数据后,要做一个 cut 检测,这个cut就是指能够把视频分段的一些点,把一个视频切成更细的 clips。
关于这个cut detection,作者对一个基础的pipeline还做了一些改进,基础的pipeline是比较视频每连续两帧之间变化的幅度,如果变化幅度很大,就认为这里是一个分解线,就要把它切成两段。但是这种情况只能检测出那种瞬间的变化,如果是渐变,是检测不出来的,所以对其进行改进,改成一个多级的边界检测(之间是检测相邻两帧,现在可能每隔几帧去看一下变化大不大,有不同的间隔模式),这样能检测出能多的边界。
把视频进行分段,切成更细的片段之后,用三种不同方法给这些视频片段打上文本标注。
3 captions
这三种方法分别是:
- CoCa:基于图像的,可能取一个中间帧,用一个图像打标签的方式,去给这个视频打上一个描述。(某一帧的内容是什么,这个视频的内容就是什么)
- V-BLIP:一种基于视频打标签的算法,具体可以先pass。(考虑视频全局的打标方式)
- 基于LLM,把前两种打标的方式进行一个综合。
这个每个视频就会有三个标注。
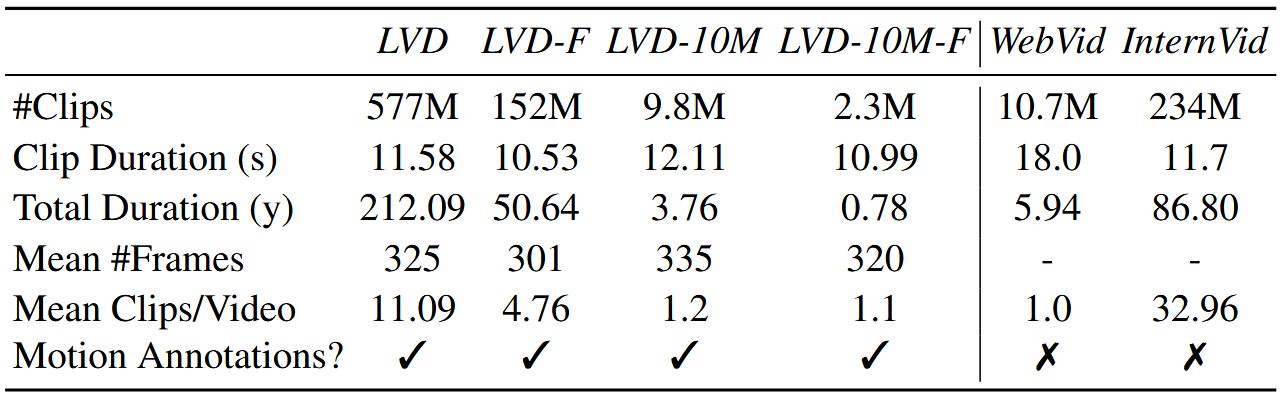
经过这两步操作,作者就收集了他的 large video datasets(表格中LVD那一列),包含了557M的clips。但是再形成LVD之后,作者做了一些实验,发现这样的数据集可能还不是最佳的,需要对这个数据集进行进一步清洗,让这个数据集质量更高,这样训出来的视频会更好。
那么接下来就是进行清洗操作。作者通过四个角度去计算了每个 视频-文本 对之间的四个评分:
- CLIP Score:计算这个视频和它的标注之间的一个匹配强度。
- Aesthetic Score:评判视频本身的美观程度。
- OCR detection Score:检测每个视频文字所占区域的面积大小。
- Optic Flow Score:检测光流,如果两帧之间的变化越大,光流得分也会越高,检测视频运动变化大小的。
得到每个视频的这四个指标后,通过这四个指标去筛选LVD数据集,让它变的更精细一点,怎么去筛呢?其实很难人为去定一个阈值,需要通过实验验证来设定阈值,在附录里有详细信息:

我以这个Aesthetic Score Thresholding 为例,它的阈值怎么取?这里有四种不同颜色的柱子:
- 蓝色:表示数据集本身不变
- 橙色:drop掉Aesthetic Score得分靠后的12.5%的数据集
- 绿色:drop掉Aesthetic Score得分靠后的25%的数据集
- 红色:drop掉Aesthetic Score得分靠后的50%的数据集
这样构成了四个不同大小的子集,然后在这四个数据集上去fine-tuning模型,生成视频后,依据 prompt alignment、quality 和它俩的混合三个指标来评估生成的视频,这里综合来看绿色的柱子最高,那就选择绿色对应的那个数据集,这样就设定好了阈值。
其他的指标也依次类推,每一个指标都会drop掉一部分数据,然后取一个交集,得到了 LVD-F。 这就是所谓的 数据治理!!!
在上面的表格中可以看到,LVD-F 大概是 LVD 的四分之一,这个 LVD-F 就是高质量的数据。
上面已经说的很详细了,下面开简答看一下作者提出的三步走。
2.2 Stage I: Image Pretraining
这部分是文生图预训练,实际上就是 Stable Diffusion,之前已经做过了,但是这里验证了一下 Image Pretraining 对视频生成的一个影响:
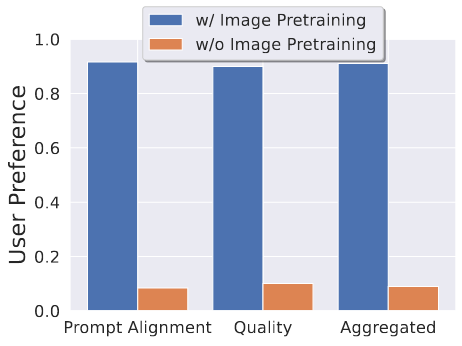
如果是基于一个文生图预训练模型基础上继续做视频生成的fine-tuning,和从头开始随机初始化做视频生成,效果差距是很大的。图中蓝色柱子就是在文生图模型基础上做,橙色柱子就是从头开始做,效果差距很大。
2.3 Stage II: Curating a Video Pretraining Dataset
这部分就是上面说的如何将一个 LVD 数据集 变成一个 LVD-F 数据集,把数据集的规模缩小到四分之一,但是质量更高。
这里也做了一个实验,就是在看做不做数据治理对模型效果的影响:
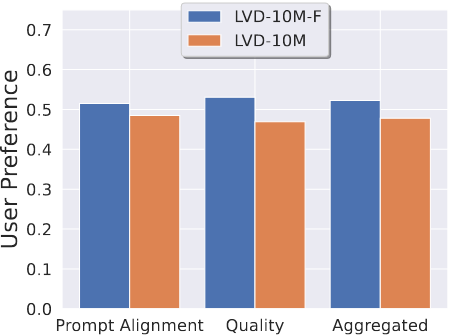
可以看到做数据治理的效果是要比不做更有优势一点,但是这个gap会比上一个小很多。
这里还做了一个实验,验证在不同的数据规模下做数据治理是不是还有用?
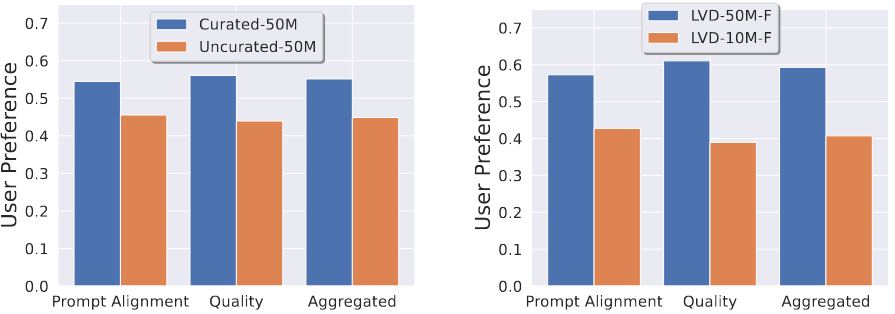
可以看到在更大规模的数据集上做数据治理还是有用的。
这部分的实验说明了两个很重要的问题:
- 数据治理很有用!!!
- 大规模数据也很有用!!!
2.4 Stage III: High-Quality Finetuning
这部分就是高质量视频的 fine-tuning,这个就针对不同的子任务,前面也说了怎么做了,这里也做了一个实验来验证第二阶段的操作对本阶段的提升:
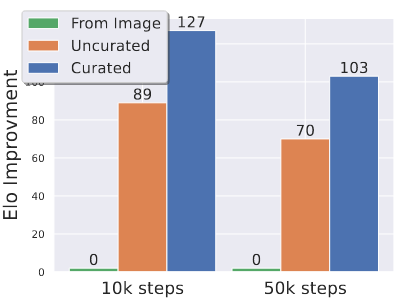
- 绿色柱子:代表用第一阶段文生图模型来作为第三阶段 fine-tuning 的初始值(跳过第二阶段)
- 橙色柱子:第二阶段用没治理过的数据pretrain后做第三阶段的 fine-tuning
- 蓝色柱子:第二阶段用治理过的数据pretrain后做第三阶段的 fine-tuning
这里可以看到第二阶段对效果的影响,肯定是用第二阶段好,而且用治理过的数据好。
这个图还能说明一个问题:随着步数的增大,第二阶段的作用会慢慢变弱。其实经没经过第二阶段只是改变了第三阶段的一个初始值,第三阶段也是能学到东西的,那么经过一段时间的学习,第三阶段也能把第二阶段缺失掉的东西补一部分回来。
其实到这里这篇工作的核心工作就说完了,后面就是在不同子任务上的具体应用,因为里面用到了LoRA,我还没详细看过LoRA,里面有些内容看不太懂,等我看完LoRA后再补上。
如果看过LoRA的话,可以重点关注一下实验部分的 Camera Motion LoRA,这个是一个比较新颖的东西,其中加LoRA模块的地方很有意思。

Horizontal LoRA:生成的视频是水平移动的;Zooming LoRA:生成的视频是不断放大/缩小的 Static LoRA:生成的视频是静止的。
- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2024/01/01/论文精读-Stable-Video-Diffusion-Scaling-Latent-Video-Diffusion-Models-to-Large-Datasets/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!