

前言:这是一篇萨里大学CVSSP组的工作,11.29日发在arxiv上,主要做的是specific categories的生成,其中涉及到了角色一致性的生成问题。
1 Abstract
提出一个新的任务:Virtual Creatures Generation
给定一组 unlabeled 图像的 target concepts(比如200中鸟),训练一个T2I模型,能够在不同的背景和上下文中创建新的 concepts。
针对这个任务提出一种新的方法: DreamCreature
用无监督方式 识别和提取 底层sub-concepts(比如狗的耳朵),T2I模型组合学习这些sub-concepts,生成新图(一个新的鸟)。
为了让这些sub-concepts一直保持不变,同时各个sub-concept之间互不影响,提出一种 textual inversion technique

最近做 personalization 是怎么做的?给定一组描述相同 concept 的图像,,它们在文本表示空间中学习了一个 dedicated token(这就是 textual inversion),这个特殊的token可以灵活的用来作为text descriptions中的代理(proxy),以生成一致的图像。它们专注于学习整体的 concept ,并将其放置在不同的背景和环境中,但是这类方法是有局限性的:
2 Method
总览
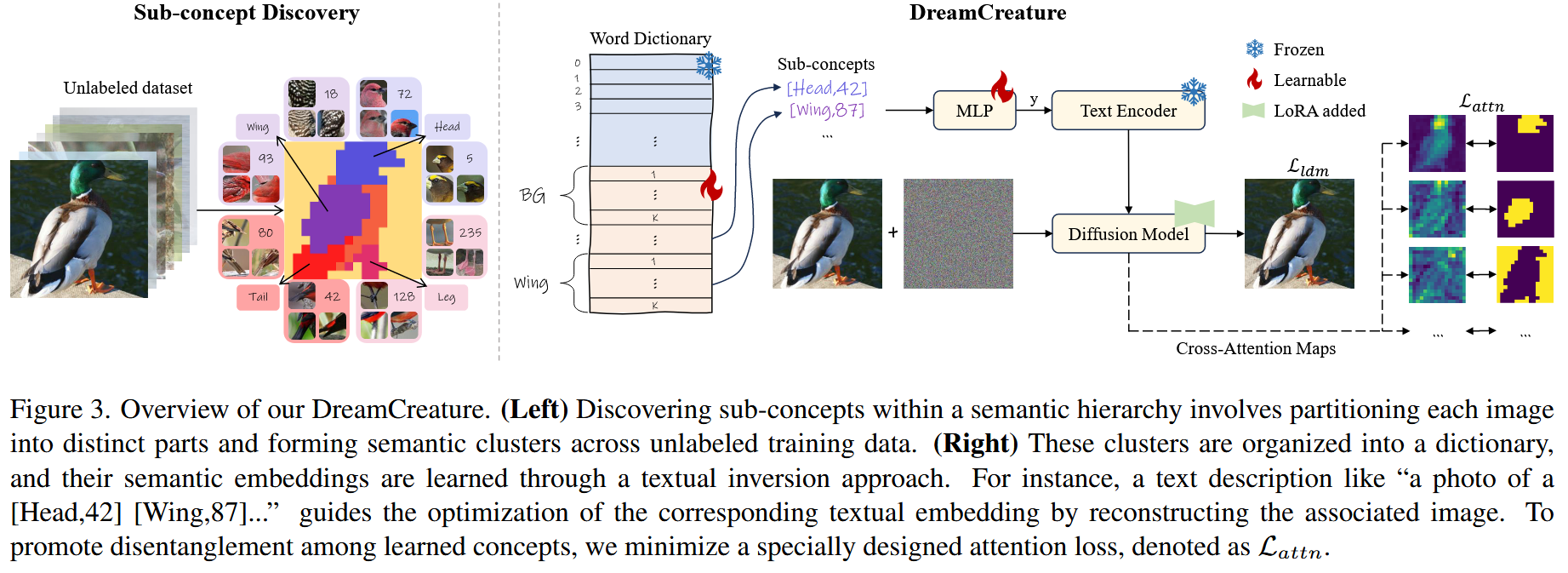
左图:在语义层次结构中发现sub-concepts涉及将每个图像划分为不同部分,并在未标记的训练数据中形成语义聚类。
右图:这些簇被组织成一个词典,并且它们的semantic embeddings是通过textual inversion方法学习的。例如,像“a photo of a [Head,42] [Wing,87]...”这样的text description指导着通过重建相关图像来优化相应的text embedding。为了促进学习概念之间的解耦,最小化了一个特别设计的attention损失,表示为\(\mathcal{L}_{attn}\)。
每个 target concept 都由一组 sub-concepts 组成,与训练图像 \(\left\{ x \right\}\) 配对,这个语义层次结构随后被用作微调T2I模型,表示为 \(\left\{ \epsilon _{\theta}\text{,}\tau _{\theta}\text{,}\mathcal{E}\text{,}\mathcal{D} \right\}\)
\(\epsilon _{\theta}\) :diffusion denoiser
\(\tau _{\theta}\) :text encoder
\(\mathcal{E} / \mathcal{D}\) :auto encoder
采用 textual inversion 技术,在 word embedding 空间中学习每个 sub-concept 的一组 pseudo-words \(p^*\) (伪词) \[ \mathcal{L}_{ldm}=\mathbb{E}_{z,t,p,\epsilon}\left[ \lVert \epsilon -\epsilon _{\theta}\left( z_t,t,\tau _{\theta}\left( y_p \right) \right) \rVert _{2}^{2} \right] \] \[ p^*=\underset{p}{arg\min}\ \mathcal{L}_{ldm} \]
\(\epsilon ~\mathcal{N}\left( 0,1 \right)\):表示伪缩放的噪音
\(t\):time step
\(z=\mathcal{E}(x)\):图像的 latent 表示
\(z_t\):时间 \(t\) 的 latent noise
\(y_p\):包含 text tokens \(p\) 的 text condition
\(\mathcal{L}_{ldm}\):是用于重构 sub-concept 的标准扩散损失
由于每个 target concept 由一组 sub-concepts 组成,因此通过重构相关的sub-concepts集来实现其重构。
2.1 Sub-concepts Discovery
这部分主要说的是个标注方法,简要说说,首先用DINO提取图像特征,得到特征图\(F\),然后进行三级分层聚类:
- 第一层:使用k-means算法在特征图 \(F\) 上应用两个簇,以获得前景和背景 \(B\)
- 第二层:k-means进一步应用于前景,以获得每个代表一个 sub-concept 的 \(M\) 个簇,例如鸟类的头部
- 第三层:进一步将每个 \(M\) 簇以及背景簇 \(B\) 分成 \(K\) 个子类。每个子类指的是进一步细分的含义,比如特定鸟类的头部或特定的背景风格
经过这步之后,图像的每个区域被标记为相应的簇的索引,这个 description 将被用作模型训练中的 text prompts(例如:“a photo of a [p]”,\(p=\left( 0,k_0 \right) ,\left( 1,k_1 \right) ,\left( 2,k_2 \right) ,...,\left( M,k_M \right)\) )
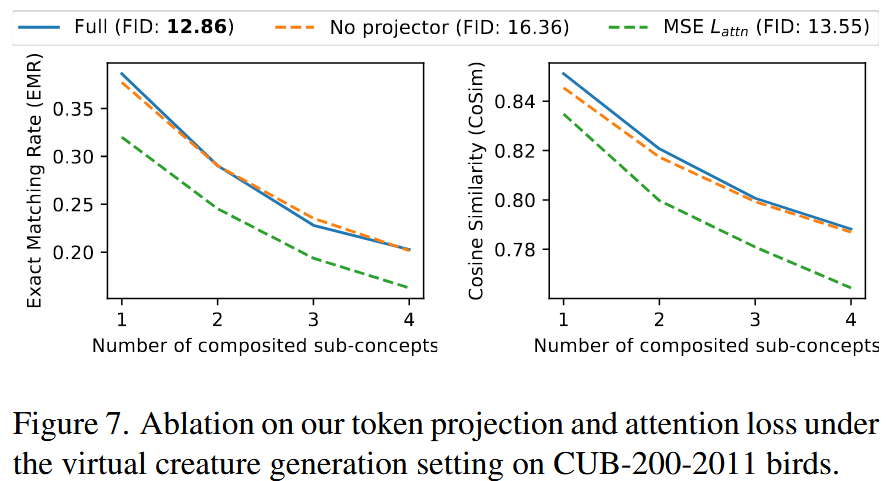
2.2 Sub-concepts Projection
这个任务需要掌握更多的 word tokens,这些 word tokens 来自 concepts 和 sub-concepts,但是这些 concepts 和 sub-concepts 带有固有的缺陷(比如部分重叠和过度切割)。
为了增强学习过程,作者这里用了两层 MLP+ReLU 激活函数的神经网络 \(f\) 。
2.3 Model Training
之前的工作已经证明,不仅要学习伪词,而且要 fine-tuning T2I模型,能够更好的实现 target concept 重建。但是fine-tuning T2I模型要付出巨大的训练成本,因此,将 LoRA 应用于 cross-attention block ,以实现高效的训练。然后最小化扩散损失 \(\mathcal{L}_{ldm}\) ,以学习伪词和 LoRA adapters。
在仅使用 \(\mathcal{L}_{ldm}\) 训练时,部分之间会发生纠缠,这一点可以从 denoiser \(\epsilon _{\theta}\) 的 cross-attention map 中可以看出:
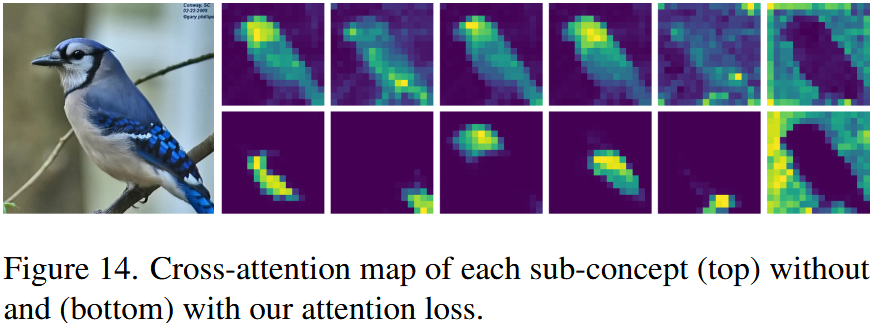
这种纠缠是由于 sub-concepts 之间的相关性而产生的(比如鸟头和鸟身总是编码配对,以表示同一种物种)
为了解决这个问题,引入一个基于熵的 attention 损失作正则化: \[ \mathcal{L}_{attn}=\mathbb{E}_{z,t,m}\left[ -\left( S_m\log \hat{A}_m+\left( 1-S_m \right) \log \left( 1-\hat{A}_m \right) \right) \right] \] \[ \bar{A}_m=\frac{1}{L}\sum_l^L{A_{l,m},\ \ \ \ \ \hat{A}_{m,i,j}=\frac{\bar{A}_{m,i,j}}{\sum_k{\bar{A}_{k,i,j}}}} \]
\(A\in \left[ 0,1 \right] ^{M×HW}\) :第 \(m\) 个 sub-concepts 和 latent noise \(z_t\) 之间的 cross-attention map
\(L\):选择的 attention map 的数量
\(\hat{A}\in \left[ 0,1 \right] ^{M×HW}\):所有 sub-concepts 的平均和标准化的 cross-attention map
\(S_m\in \left[ 0,1 \right] ^{M×HW}\):用作只是 \(m\) 部分位置的 mask
如果图像中不存在 sub-concepts (例如被遮挡住了),那么 \(S_m\) 和 \(\hat{A}_m\) 都设置为 0
总loss: \[ \mathcal{L}_{total}=\mathcal{L}_{ldm}+\lambda _{attn}\mathcal{L}_{attn},\ \ \ \ \lambda _{attn}=0.01 \] 这样的 attention loss 可以直观的确保 sub-concepts 在特定位置只出现一次,在去噪过程中更容易于其他 sub-concepts 分离,为特定位置生成 sub-concepts 时,扩散模型应该只关注该 sub-concept,而不是其他无关的 sub-concepts,实验中已经验证了这种设计的有效性:
3 Experiments
Datasets
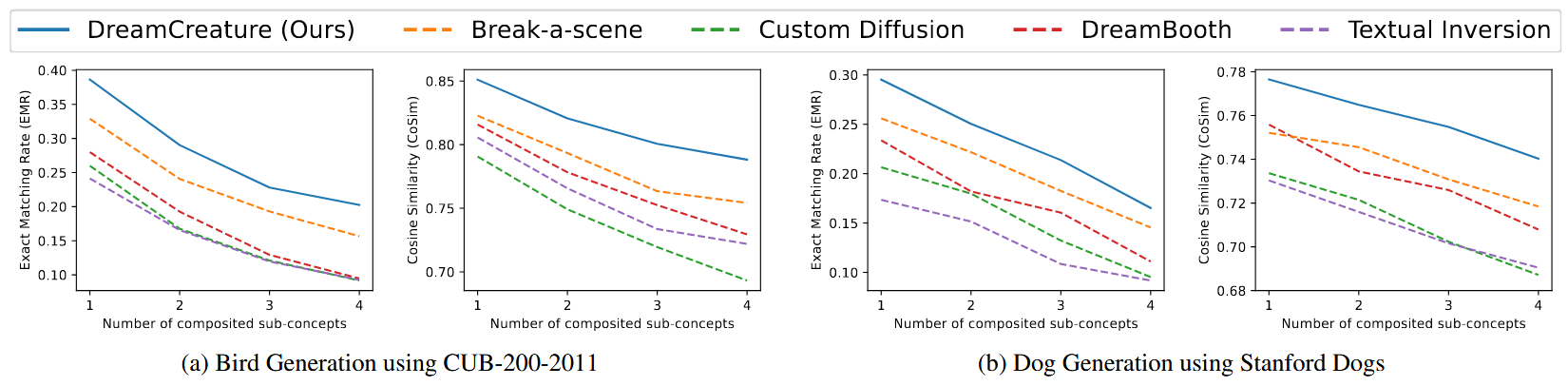
作者就试了两个种类,一个鸟一个狗,是不是人脸的效果不好啊
CUB-200-2011 (birds 5994 training images)
Stanford Dogs (dogs 12000 training images)
卡
单卡 3090 时间没说 应该不长
最后看看效果:
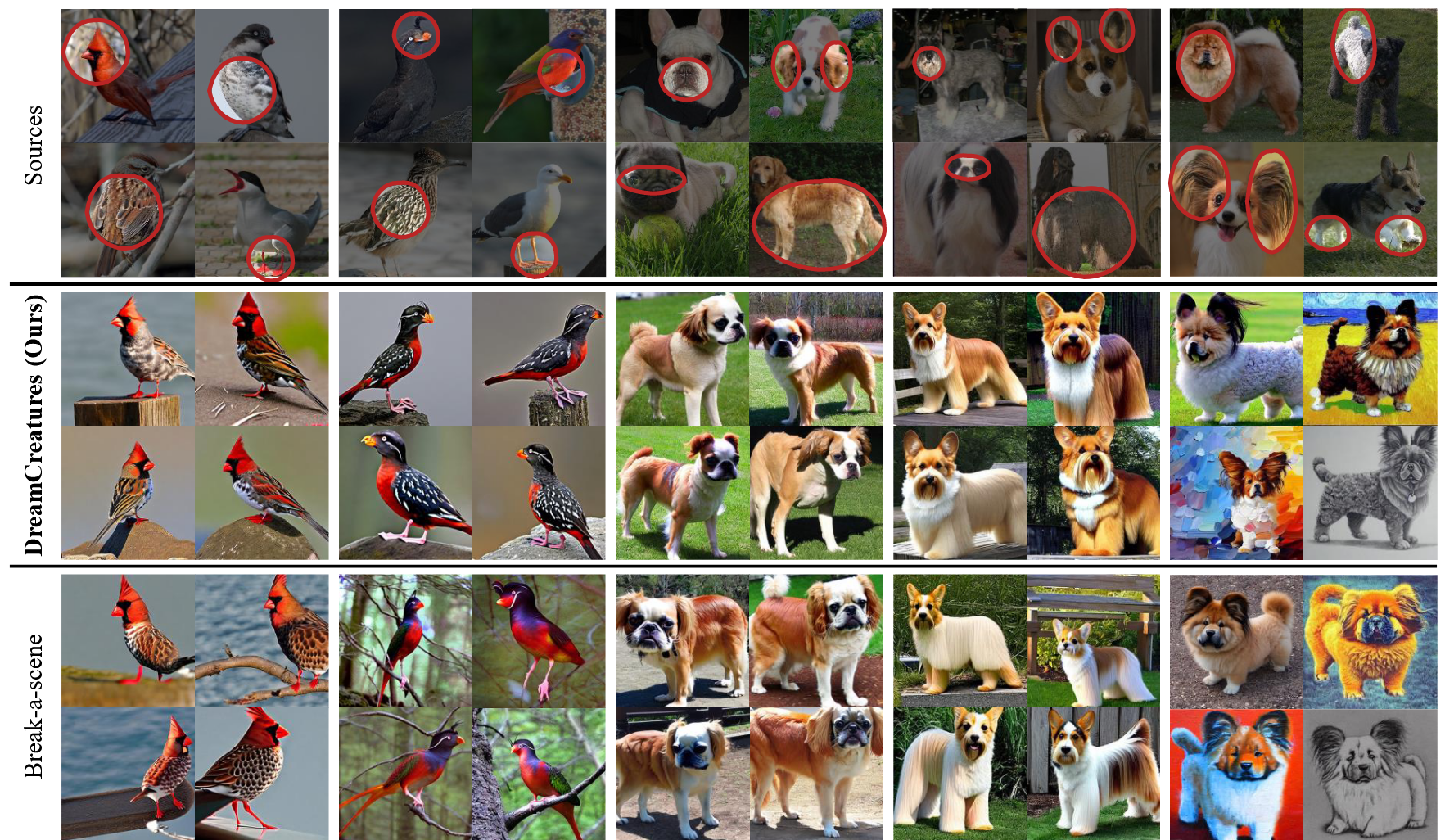

- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2024/01/14/论文精读-DreamCreature-Crafting-Photorealistic-Virtual-Creatures-from-Imagination/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!