

前言:23年12月发在arxiv上,MIT 和 Adobe 联合发的,做的是 T2V,通过定制动作来增强T2V模型,甚至还有一定的拓展能力,超出训练中的动作。
重点关注:对特定参数微调的想法、加新的正则化的想法
1 Abstract
这篇工作引入了一种方法,用于通过定制动作来增强 T2V 模型,通过利用几个展示特定动作的视频样本作为输入,扩展其能力,使其超越原始训练数据中描绘的动作。
贡献三点:
- fine-tuning 了 T2V 模型,以学习输入中所描绘的动作与新的特殊 token 之间的映射。为了避免过拟合到新动作,引入了一种新的正则化方法。
- 利用预训练模型中的运动先验,这个方法可以生成自定义动作的新视频,并将该动作与其他动作结合起来,还扩展到了个性化主体的动作和外观的多模态定制。
- 引入了新的定量评价指标。
motivation
现在的 T2V 模型能力局限与它的训练数据,想传达训练集中未涵盖的特定动作是很难的,例如下面的图片,左边的输入视频中的舞蹈很难用语言来描述,理想的输入结果是右侧所示,那么就引入一个问题:如何利用现有的 T2V 模型对于动作和外观的先验,同时又增加了新的、定制的动作?

2 Method
目标:根据一种新的动作来定制 T2V 模型。换句话说就是希望在模型的先验中引入新的动态概念,并将其与独特的 token 相关联。
2.1 Text-to-Video Diffusion Model Preliminaries
这节主要是对 T2V 模型进行介绍,就简单说说。
视频 \(x\) 用 latent vector 表示,text condition \(c\) 通过 text encoder 进行编码,从高斯分布中采样初始噪声图 \(\epsilon\),还是算 \(x_t\),\(x_t=\sqrt{\alpha _t}x_0+\sqrt{1-\alpha _t}\epsilon\) ,\(x_0\) 是原始视频,模型 \(\epsilon _{\theta}\) 的参数 \(\theta\) 通过以下加权去噪损失进行训练: \[ \mathcal{L}_{\theta \left( x,c \right)}=\underset{\epsilon ~\mathcal{N}\left( 0,1 \right) ,t~f\left( t \right)}{\mathbb{E}}\left[ w_t\lVert \epsilon _{\theta}\left( x,\epsilon ,c,t \right) -\epsilon \rVert _{2}^{2} \right] \] 推理的时候,通过对高斯噪声样本 \(\epsilon\) 和 text prompts 进行采样,生成新的视频,\(w_t\) 是控制样本质量的用户定义的变量。
2.2 Approach for Motion Customization
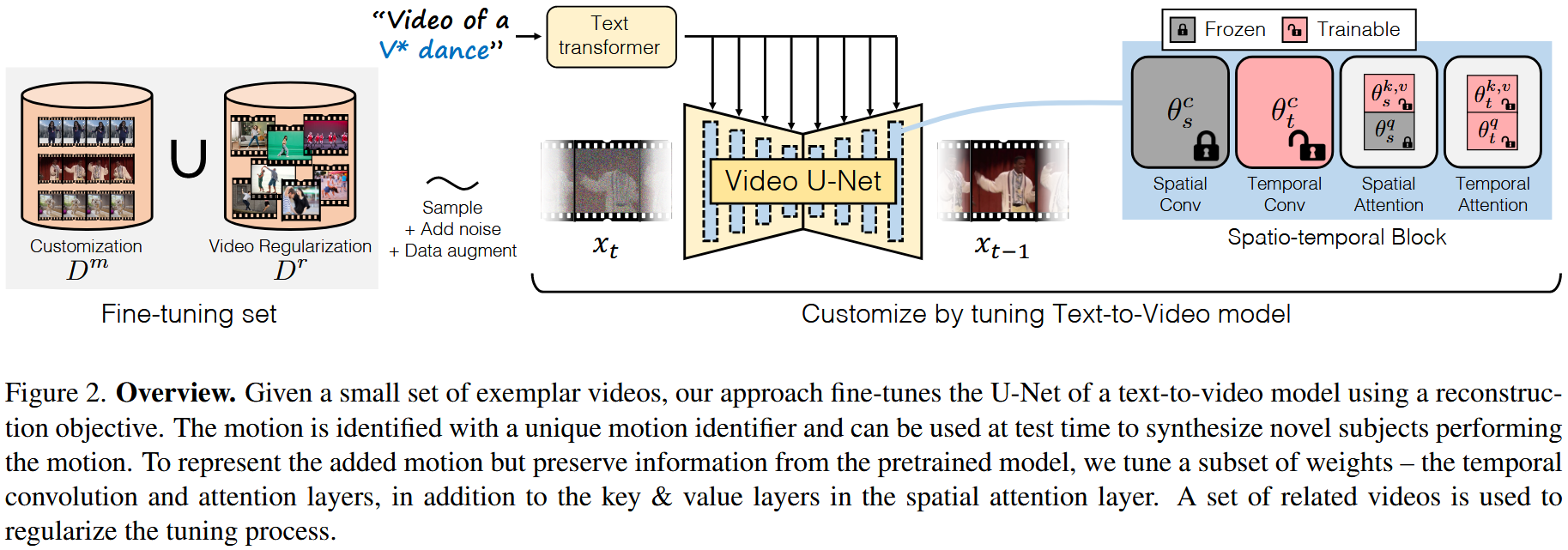
让动作通过一小组视频和相应的 text prompt 来表示 \(D^m=\left\{ \left( x^m,c^m \right) \right\}\),这种动作可以由不同的对象在不同的背景中执行,视频中的共同点是纯粹的动态动作。在视频中选择一个通用的 text description,比如“ a person doing the V* ”,实验中用"pll"这样的特殊 token 作为 “V*”。为了定制T2V模型的参数 \(\theta\),最小化之前loss的总和来 fine-tuning 模型的参数: \[ D^m=\left\{ \left( x^m,c^m \right) \right\} \] 测试时是通过文本来控制的。
2.2.1 Choice of customization parameters
新的运动视频的质量和泛化能力取决于在自定义过程中更新模型参数的选择。T2V 模型 \(\epsilon _{\theta}\) 具有可以分类到:
- 在时间维度 \(\theta _t\subset \theta\) 上的操作
- 在空间维度 \(\theta _s\subset \theta\) 上的操作(每帧)
让 \(\theta _{s}^{k,v}\subset \theta _s\) 成为空间 cross-attention 模块的 key 和 value 的参数。
temporal layers \(\theta _t\subset \theta\) 是 transformer 和 temporal convolutions,负责对帧和帧之间的 temporal patterns 进行建模,之后的实验中证明:单独的 temporal layer 不能有效的对由于时间变化的外观变化而产生的新 motion pattern 进行建模。(例如一个在3D空间旋转的物体,这需要模型生成未遮挡表面的外观)
所以还修改了 spatial layers(空间层)中的一部分参数:spatial keys/values \(\theta _{s}^{k,v}\) ,temporal \(\theta _t\) 。之前的图像定制工作中已经显示出图像模型中的 cross-attention 模块的 spatial key 和 value 足够强大,可以表示新概念的外观。后续的实验还证明,调整这些参数对运动定制任务是有效的。
2.2.2 Video regularization
之前工作表明,直接优化方程(上面那个求和最小化的方程)会导致遗忘相关概念或类别的问题(例如如果concept是一个特定的人,所有人都开始变得像那个人),为了减轻这种现象,最近的研究通常是加一个正则化集,这里也差不多,试图减轻模型对已经学到的相关动作的遗忘。
考虑基于视频的正则化,让 \(D^r\) 成为一组带有 text prompts 的配对视频的正则化,这些视频与目标定制动作视频 \(D^m\) 具有相似但不完全相同的动作。比如我想学习街舞,选择一组包含人们跳舞的真实视频进行正则化,为了实现定制化,将扩散目标 \(\mathcal{L}_\theta\) 优化到目标定制视频 \(D^m\) 和正则化集 \(D^r\) 上。 \[ \underset{\theta}{\min}\sum_{\left( x,c \right) ~D^m\cup D^r}{\mathcal{L}_{\theta}\left( x,c \right)} \] 后面实验证明,使用真实视频作为正则化集要优于使用模型生成的视频,使用模型生成的模型做正则化会大幅降低定制模型的质量。
2.2.3 Learning the motion patterns
为了促进对 \(D^m\) 中常见动作的学习,在训练过程中,目标是强调视频中的动作模式,而不是展示动作的外观或主体。例如在学街舞的情况下,希望捕捉舞蹈的动作模式,而不是背景或个别表演者的外观。
扩散模型中的去噪过程对高斯噪声进行采样,然后逐渐去除噪声。初始噪声以及早期的去噪步骤对视频的整体动态结构有很大影响,而后期阶段对应于更精细的细节。为了专注于视频的动态结构并减弱执行运动的对象的外观,作者定义了一个时间步长采样策略。具体而言借鉴了开发了一个非均匀采样策略用于生成静止图像。
这快他论文里讲的不是很清楚,需要去看代码,这块倒是很值得借鉴。
2.2.4 Customizing appearance and motion
新subject的外观通过示例数据集 \(D^s\) 来表示,该数据集由静态图像对和描述图像的caption组成。
为了学习一个人的外观,更新模型的空间层,并优化与 subject 相关的文本嵌入。首先使用动作对模型进行自定义,然后同时训练外观和 subject ,选择小批量数据集中的任一数据集示例。在学习 subject 时,将图像视为单帧视频,并仅更新所选的空间层。
其实整体的细节讲的不是很多,得好好看这篇工作的实验。
实验
T2V 模型用的是 ZeroScope
datset:ExponentialML 这个数据集不确定,再看看
GPU:单卡 A100 没说时间
结果还是很可观的:

- 本文作者: 李宝璐
- 本文链接: https://libaolu312.github.io/2024/01/15/论文精读-Customizing-Motion-in-Text-to-Video-Diffusion-Models/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!