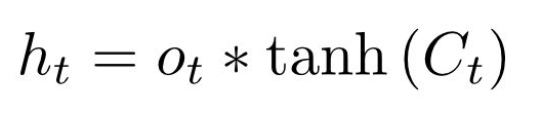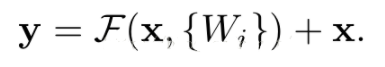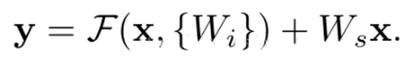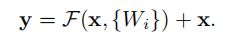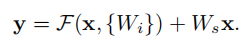一、VGG网络的背景
AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。
而VGG的作者们则选择了另外一个方向,即加深网络深度。
VGGNet的网络结构简单、规整且高效。VGGNet较为典型的网络结构主要有VGG16和VGG19(两者并没有本质上的区别,只是网络深度不一样)。
二、VGG网络结构
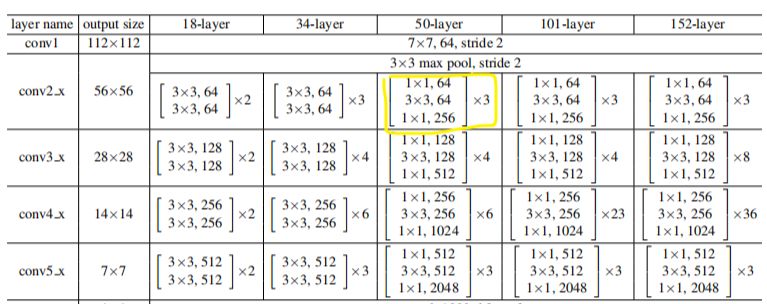
1、各网络结构参数图示
接下来以VGG16为例子来进行讲解
2、输入
(224,224,3)的RGB图像作为输入
3、双层 —— 一层卷积+(一层卷积+最大池化)
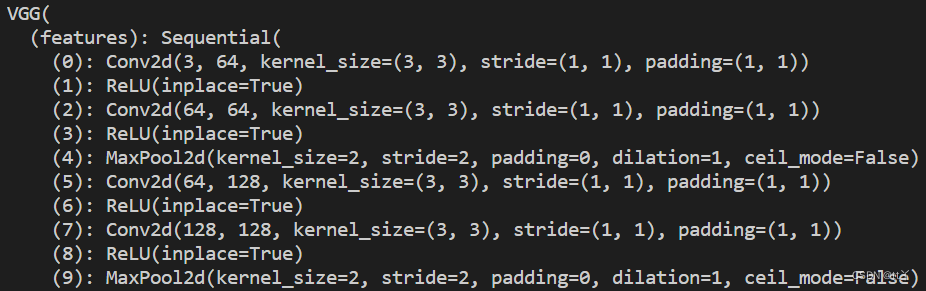
这里总共4层。
都是使用卷积核为(3,3)的卷积层,每过一层(不含池化)尺寸不变,每过一层池化尺寸减半。
因此(224,224,3)->(224,224,64)->(112,112,64)->(112,112,128)->(56,56,128)
4、三层 —— 两层卷积+(一层卷积+最大池化)
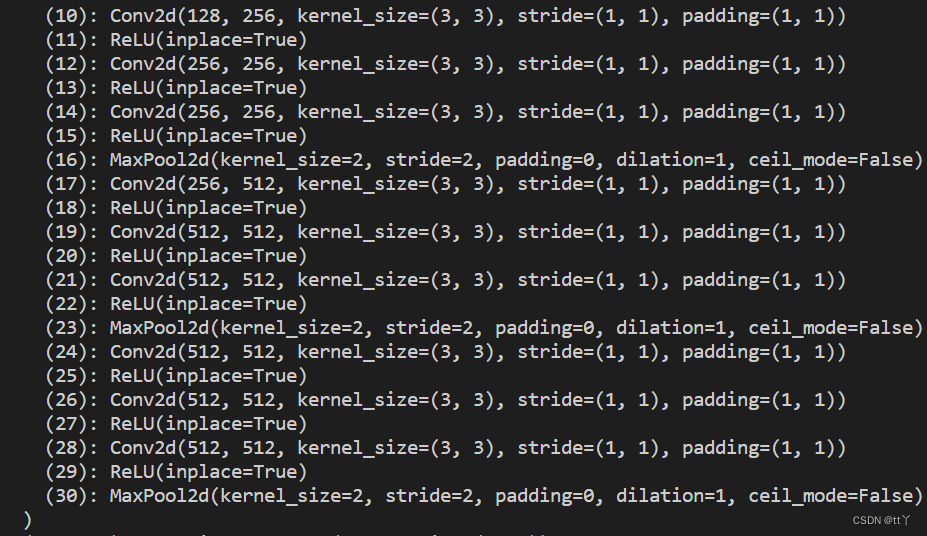
这里总共9层。
因此(56,56,128)-> (56,56,256)-> (28,28,256)-> (28,28,512)-> (14,14,512)-> (7,7,512)
5、全连接层——分类判决
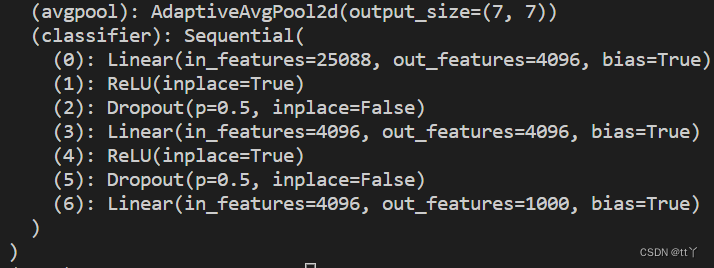
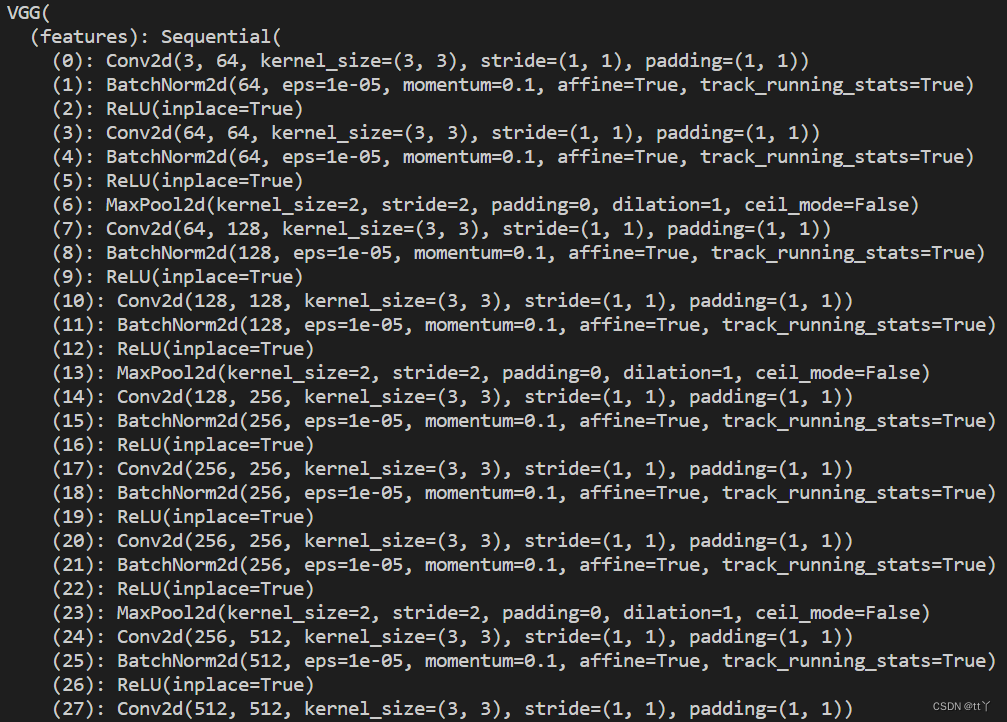
6、拓展:VGG16_bn —— Batch Normalization
就是在提取特征的每一层多加了BatchNorm2d层。
通常来说,数据标准化预处理对于浅层模型来说就够了(使得输入数据在各个特征的分布相近,往往更容易训练出有效的模型),但对于深层模型来说,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化,这种不稳定性难以让我们训练出有效的深度模型。
因此,批量归一化应运而生。
BatchNorm2d层的作用是:进行批量标准化处理(对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次。),这样能把输入的数限制在一个范围内,把数据重新变为正态分布。
公式:
![\hat{x}=\frac{x-\operatorname{mean}[x]}{\sqrt{\operatorname{Var}[x]+e p s}} * \gamma+\beta](/2022/07/01/VGG/beta.png)
而上面的可训练参数(拉伸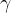 和偏移
和偏移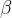 )也可以根据学习得到不一样的结果,甚至可以不使用批量归一化(
)也可以根据学习得到不一样的结果,甚至可以不使用批量归一化(
.png)
上面所说的是训练时的批量归一化,而在预测时的批量归一化则通常使用移动平均估算整个训练数据集的样本均值和方差,并使用它们得到确定的输出。
(Note:使用批量归一化训练时可以把批量大小设得大一些,从而使批量内样本的均值和方差的计算都较为准确。)
具体结构如下:
三、VGG网络的亮点——连续小卷积核代替大卷积核
采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)
对于给定的感受野,采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层(3个33卷积附带3个ReLU,而一个77卷积只附带一个ReLU)可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样可以在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
替代原因:
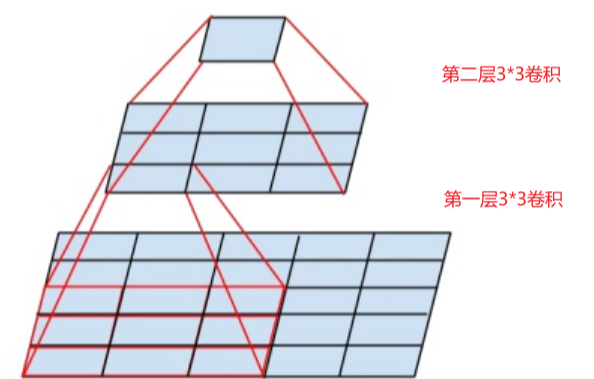
如图所示,最上面的那个特征最终是由下面55的特征得到的,这样的效果跟一层55卷积的效果一样。
参数:332<5*5
四、VGG网络的不足
耗费更多计算资源,并且使用了更多的参数(这里不是因为多层3x3卷积),导致更多的内存占用。其中绝大多数的参数都是来自于第一个全连接层。
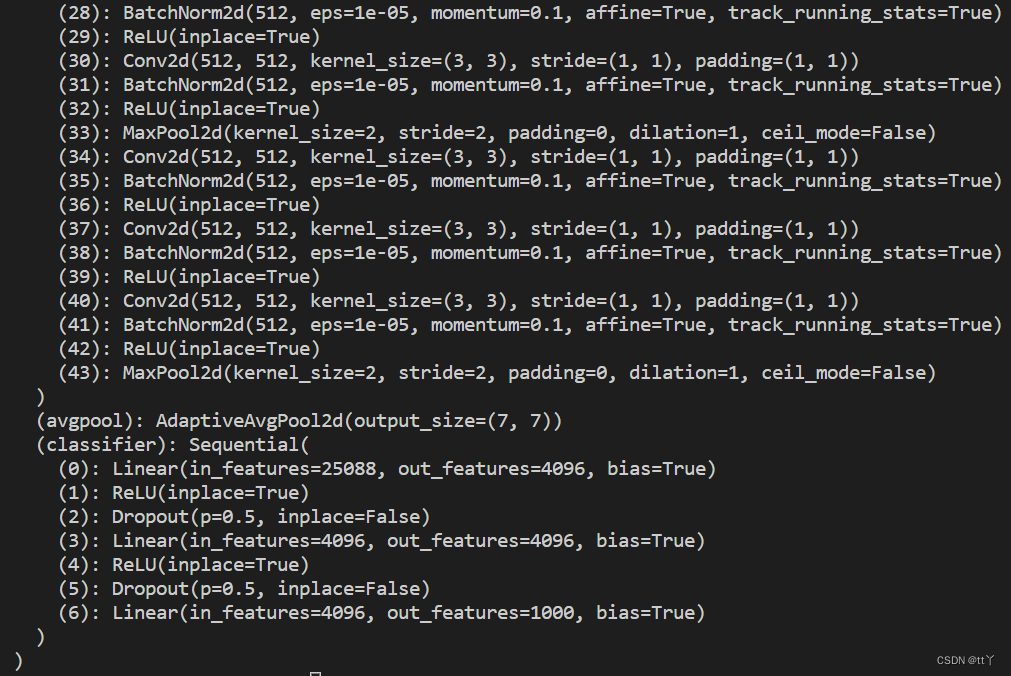
五、VGG代码实现
这里只展示模型架构。
1 | import torch |
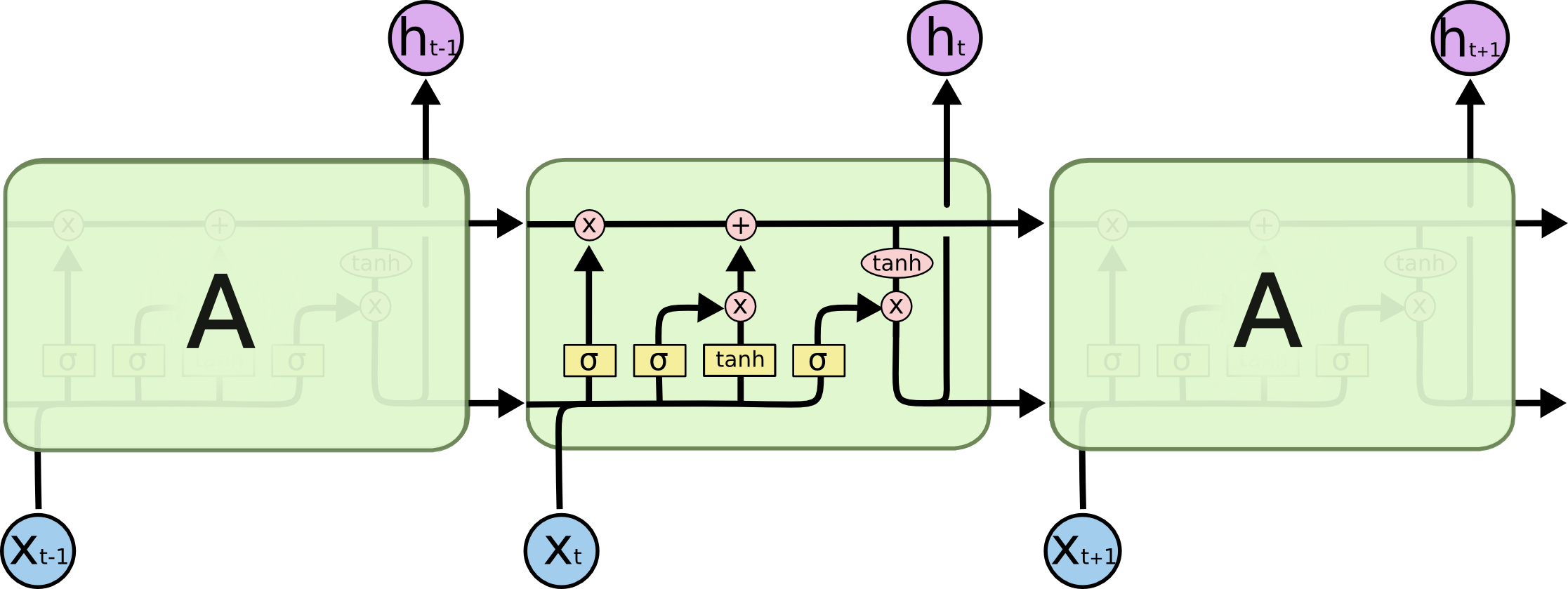
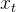 :当前时刻输入信息
:当前时刻输入信息 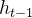 :上一时刻的隐藏状态
:上一时刻的隐藏状态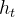 :传递到下一时刻的隐藏状态
:传递到下一时刻的隐藏状态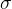 :
: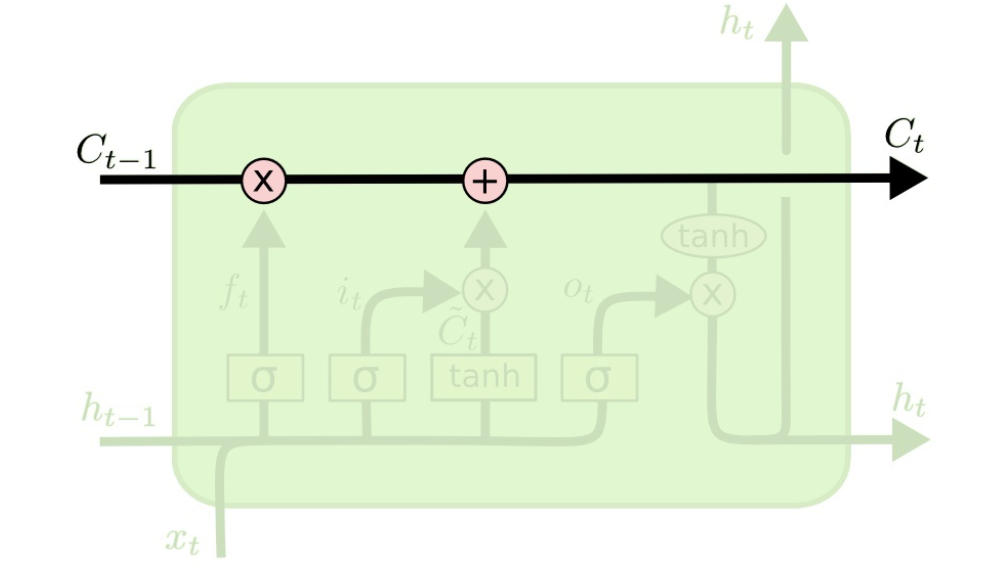
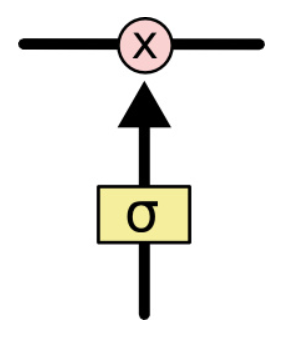
 ,作用是控制细胞状态中的信息进行选择性的遗忘,决定哪部分需要丢弃,哪些需要保留。那么是如何控制细胞状态选择性遗忘记忆的呢,我们结合公式来看:
,作用是控制细胞状态中的信息进行选择性的遗忘,决定哪部分需要丢弃,哪些需要保留。那么是如何控制细胞状态选择性遗忘记忆的呢,我们结合公式来看: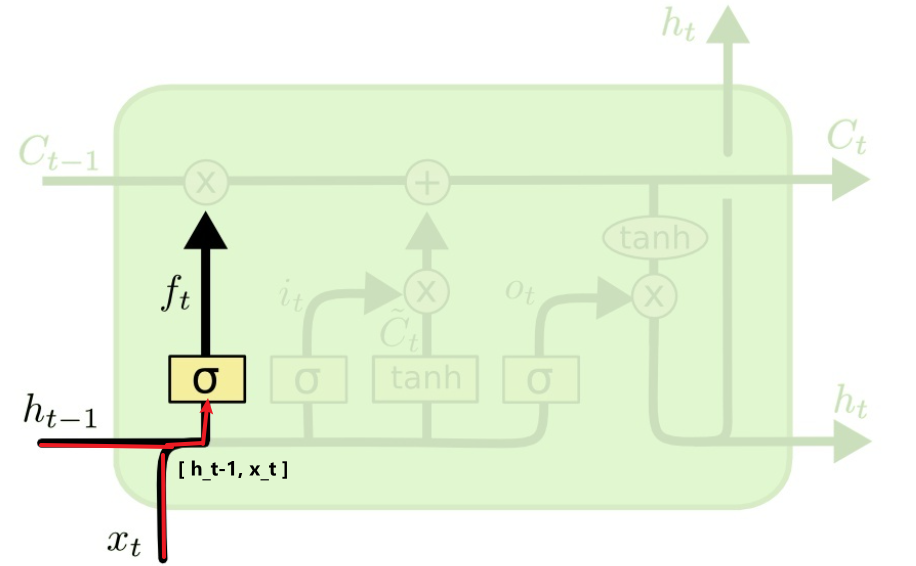
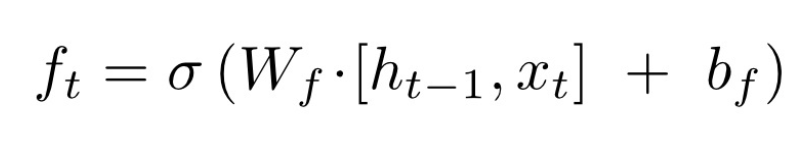
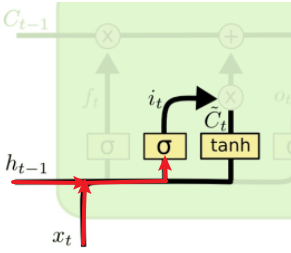
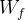 对
对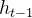 和
和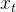 拼接而成的矩阵进行矩阵相乘,再加上偏置
拼接而成的矩阵进行矩阵相乘,再加上偏置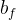 ,投入到sigmoid函数中,得到一个与
,投入到sigmoid函数中,得到一个与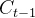 相同维度的矩阵
相同维度的矩阵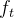 , 比如,得到
, 比如,得到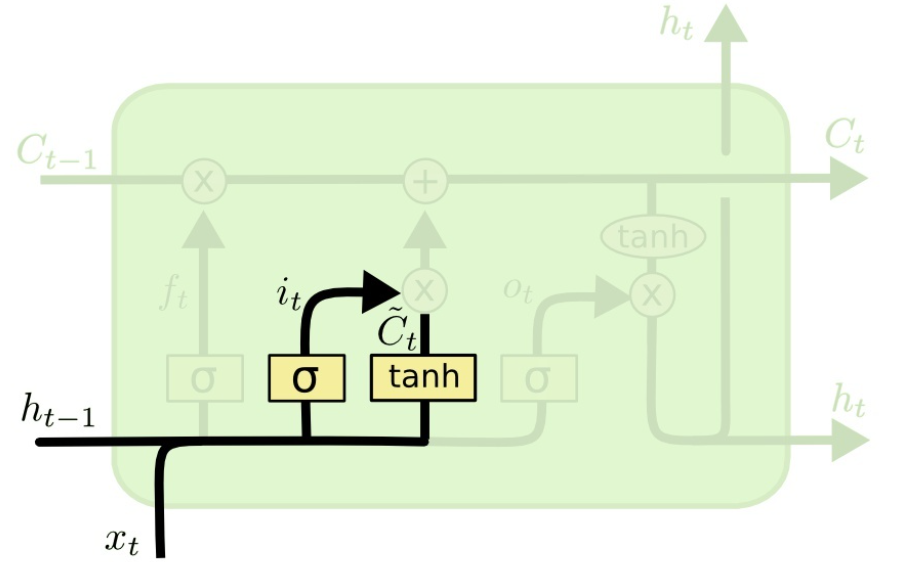
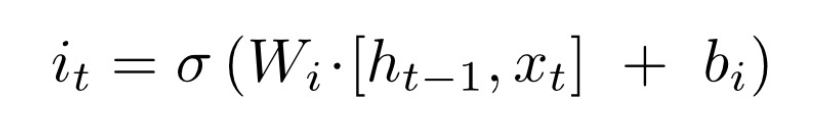
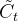 相同维度的矩阵
相同维度的矩阵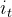 , 比如,得到
, 比如,得到 和
和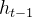 中的信息,然后与
中的信息,然后与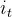 的值点乘,来决定哪些记忆是有用的,依然
的值点乘,来决定哪些记忆是有用的,依然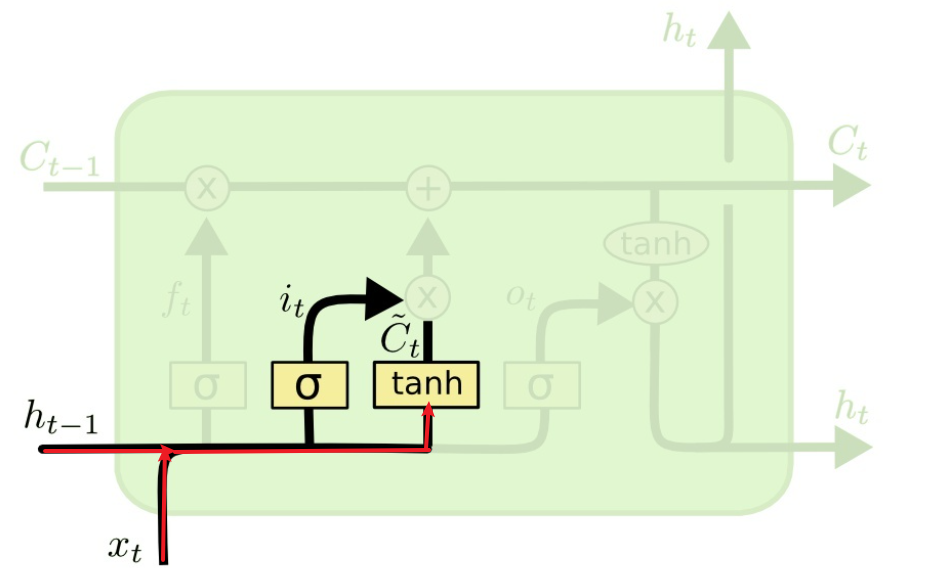
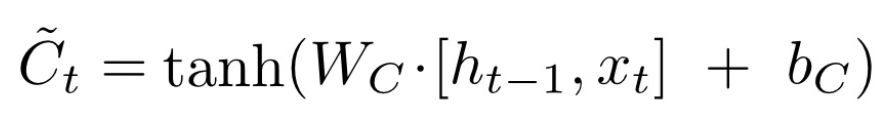
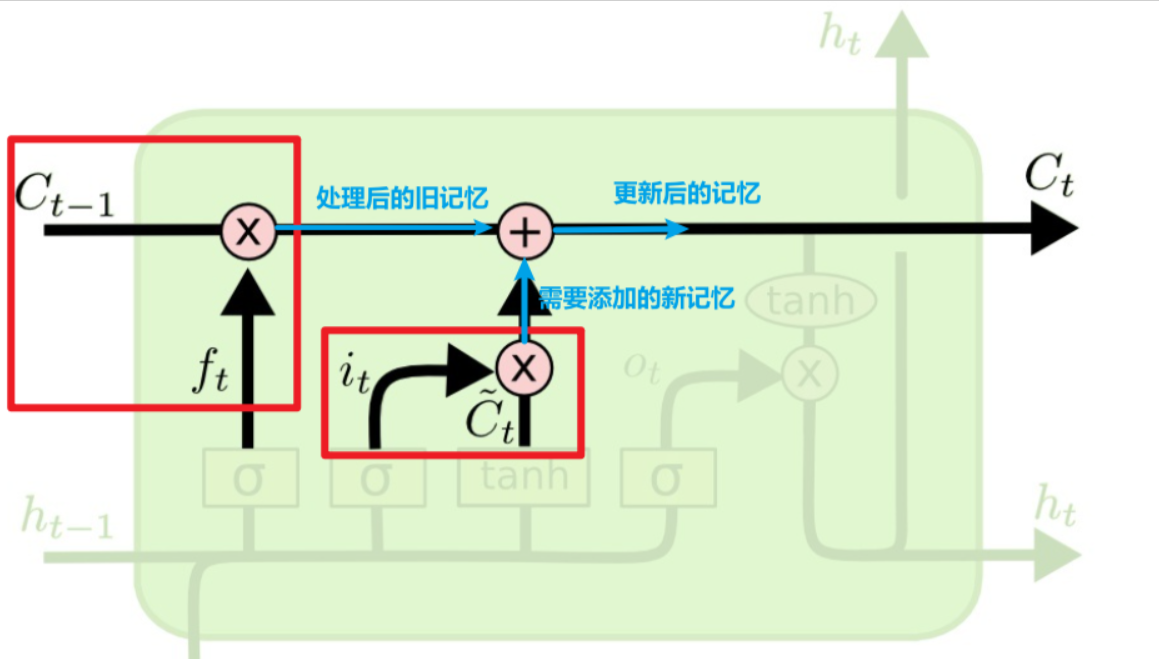
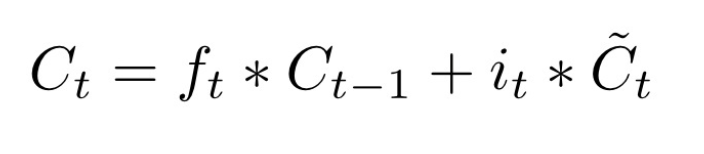
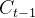 表示处理后的旧记忆,
表示处理后的旧记忆,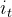 点乘
点乘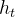 ,这个输出是以新的细胞状态
,这个输出是以新的细胞状态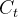 为基础的,分两部分进行。
为基础的,分两部分进行。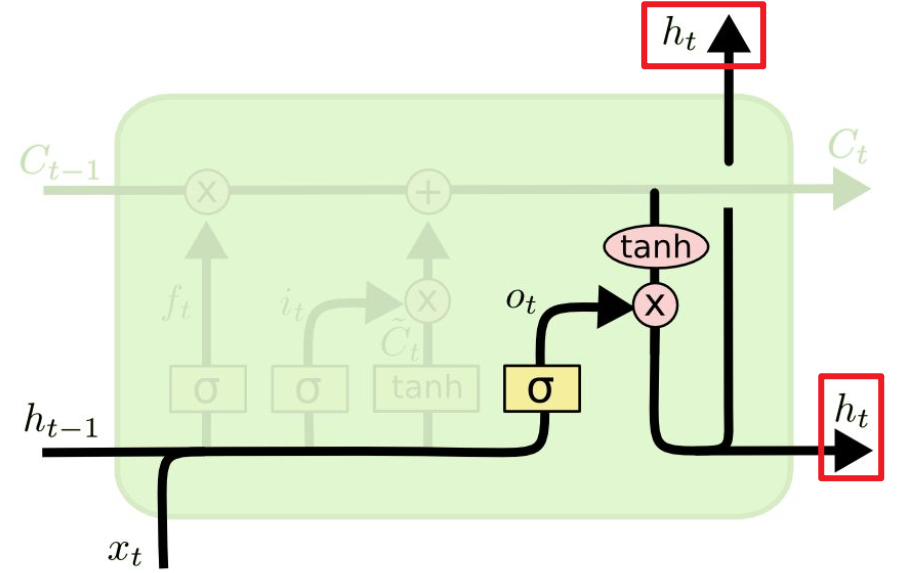
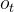 ,比如
,比如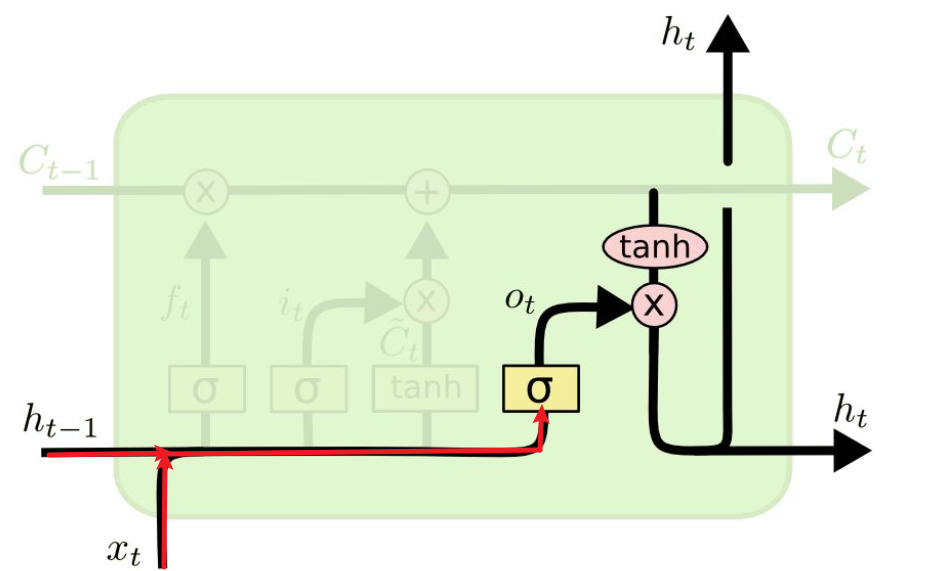
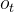 的公式:
的公式: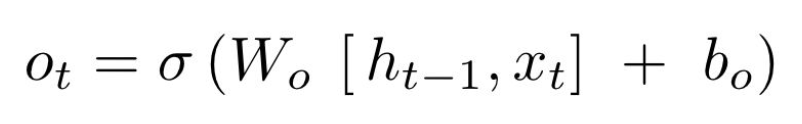
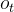 ,来控制哪部分需要输出。
,来控制哪部分需要输出。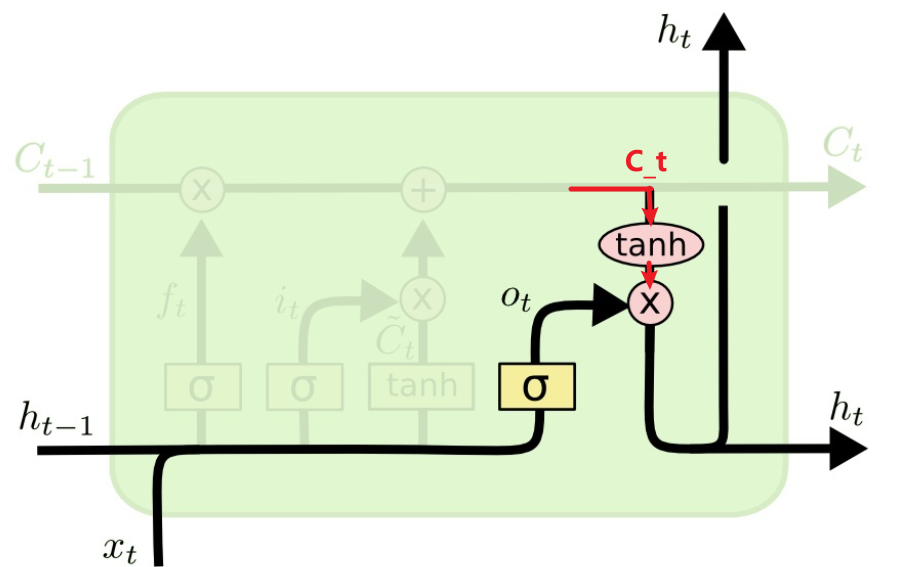
 的公式:
的公式: